
5 AI Questions Every Product Manager is getting Asked

She had eight years of product experience. Three products with 10 million-plus DAU. Six weeks of dedicated interview prep.
She got eliminated in Round 2.
Not by a trick question. Not by a culture fit screen.
By a single follow-up about how she would evaluate whether a RAG pipeline was retrieving the right documents.
She knew what RAG was. She could draw the architecture diagram.
But the interviewer did not want a diagram. He wanted to know what she would do when the retriever pulled the wrong documents at 2 am on a Tuesday and support tickets started spiking.
She did not have that answer.
Here is the part that should concern you. She was not underprepared. She was prepared for the wrong interview.
The AI PM interview in 2026 is a fundamentally different game. Most candidates are still running the old playbook.
CIRCLES. RICE. Feature prioritisation matrices. These are table stakes now.
Nobody gets hired for knowing them. You just get disqualified for not knowing them.
The real filter is AI depth.
I have spent two years shipping AI products in production. I have also helped 1000+ PMs prepare for AI roles. See testimonials
The pattern is impossible to miss. Five concepts keep showing up. Not ten. Not twenty. Five.
The dangerous part is not that PMs have never heard of them. Most have.
The dangerous part is that most PMs know these concepts at exactly the depth that gets them eliminated.
Let me show you what I mean.
1. RAG (Retrieval-Augmented Generation)
You probably already know what RAG is.
An LLM does not know everything. It hallucinates. It has no access to your company’s internal data. So you add a retrieval step. You search a vector database for relevant documents first. Then you feed those documents to the LLM as context. The LLM generates an answer grounded in actual information instead of its training data.
That explanation is correct. It is also the exact answer that gets you a polite nod followed by a harder follow-up.
RAG has a dirty secret. The retrieval step fails silently. The LLM does not tell you it received the wrong documents. It generates a confident, articulate, completely wrong answer. Your user has no idea. Your metrics might not catch it for weeks.
So the real question is not what RAG is. The real question is what you do when the R in RAG stops working.
How do you measure retrieval quality separately from generation quality?
When do you chunk documents into smaller pieces versus keeping them whole.
What happens when the user query is ambiguous, and the retriever returns five documents that are each partially relevant, but none exactly right?
What happens when you stuff too many documents into the context window and the LLM starts ignoring the important ones because of lost-in-the-middle effects?
These are the questions that separate PMs who have read about RAG from PMs who have debugged RAG in production.
Interviewers expect you to go deeper than this.
Sample Interview Questions
Q1. You are building a customer support chatbot using RAG. Users report that 30% of answers are irrelevant. How would you diagnose whether the problem is in retrieval or generation?
Q2. Your RAG system retrieves the correct document, but the LLM still produces an incorrect answer. What could be going wrong, and how would you fix it?
Q3. A stakeholder wants to add RAG to a feature that currently uses a fine-tuned model. How would you evaluate whether this is the right architectural decision?
Real AI PM Interview Questions (With Detailed Solution) Here
2. Evals (AI Evaluation)
Here is a question that sounds easy.
Your model accuracy improved from 84 % to 91 %. Should you ship it?
Answer it in your head right now.
If your instinct was yes, ship it; accuracy went up, you just failed the interview.
If your instinct was it depends, good. But the interview is only beginning. Because the next question depends on what. And that is where most candidates fall apart.
Most PMs treat evaluation as a checkpoint. Model hits a number. You ship. But AI evaluation is not a checkpoint. It is a continuous argument between what the model does well and what the business actually needs.
There are two worlds of evals, and most PMs only live in one.
Offline evals measure model performance before deployment. You run test datasets. You calculate precision, recall, and F1. You compare against baselines. This world feels safe. The numbers are clean. The comparisons are neat.
Then there is the second world. Online evals. What happens after deployment? User satisfaction. Task completion rates. Time to value. Edge cases your test data never imagined. The queries that real humans type at 11 pm on their phones look nothing like your curated evaluation dataset.
The gap between these two worlds is where AI products go to die.
A model can score 95% on your offline eval set and still make users miserable. Your eval set was built by engineers who write clean, well-structured queries. Your actual users write things like why is this broken and fix it and paste in screenshots of error messages.
The PM who wins the interview connects eval metrics to business outcomes. Not accuracy went up 7%. Instead. Accuracy went up 7%. Did user satisfaction improve? Did support tickets decrease? Did the revenue metric move? If you cannot draw that line from model metric to business metric, you will hear the worst four words in any interview. Let us move on.
Interviewers expect you to go deeper than this.
Sample Interview Questions
Q1. You are the PM for an AI content moderation system. Precision is 97 percent but recall is 72%. The policy team wants a higher recall. The UX team is worried about false positives. How do you navigate this tradeoff?
Q2. Design an evaluation framework for an AI feature that recommends products. What offline and online metrics would you track, and how would you decide when the model is ready to ship?
Q3. Your A/B test shows the new model has 3% better accuracy but 15% higher latency. How do you make the ship or no-ship decision.
3. Fine-Tuning vs Prompting
This is the concept where interviewers separate PMs who have shipped AI from PMs who have read blog posts about AI.
The question usually lands like this. Your AI feature is producing mediocre outputs. You have three options. Better prompts. Fine-tuning. A larger model. How do you decide?
Most candidates give a vague cost-benefit answer. Fine-tuning is more expensive but more accurate. Prompting is cheaper but limited. That answer is technically correct. It is also useless to the interviewer. Because they already know the textbook tradeoffs. What they want to hear is your decision framework. The actual sequence of steps you would follow.
Here is one that works.
Start with prompting. Always. Every single time. It is free to experiment with. You can iterate in hours, not weeks. A well-crafted prompt with good examples solves 80% of problems that PMs instinctively want to throw fine-tuning at.
But sometimes, prompting plateaus. You have tried ten prompt variations. You have added a few-shot examples. Quality is stuck at decent, and your users need excellent. Now you have a real decision to make.
Ask one question. Why is the model failing?
If the model is missing domain-specific knowledge or terminology, fine-tuning is probably the answer. A general model does not know your company’s product taxonomy. It does not understand your industry’s jargon. Fine-tuning teaches it patterns it has never seen.
If the model simply is not capable enough for the reasoning required, try a larger model first. Sometimes the problem is not knowledge. It is raw intelligence. A bigger model might handle the complexity without any fine-tuning at all.
Here is the layer that most PMs miss entirely. This is not just a technical decision. It is a product and business decision.
Fine-tuning means you now own a model. You need labelled training data to build it. You need ML engineers to maintain it. You need to retrain it when the underlying data distribution shifts. You have just taken on a recurring operational cost that compounds with every model update.
As a PM you need to justify that investment. What is the incremental quality gain? Is it large enough to warrant the ongoing maintenance burden? Could you get 70 % of the benefit with a smarter prompt and zero operational overhead?
That is the thinking interviewers want to hear. Not fine-tuning is better. But here is how I would make the decision and here is what I would measure to validate it was correct.
Interviewers expect you to go deeper than this.
Sample Interview Questions
Q1. You are the PM for an AI writing assistant. Users complain that outputs feel generic and do not match their brand voice. Walk through how you would decide between prompt engineering, few-shot examples, and fine-tuning.
Q2. Your team fine-tuned a model six months ago. Performance has degraded. What could be causing this, and what is your plan?
Q3. A competitor just shipped a similar feature using GPT-4o. Your team uses a fine-tuned, smaller model that is cheaper but less capable. How do you think about this competitive dynamic?
Real AI PM Interview Questions (With Detailed Solution) Here
4. Agents
Pay close attention to this one. If you are interviewing in the second half of 2026, agents will likely be the longest segment of your interview.
Every major tech company is building agent-based products right now. Not planning them. Building them. Shipping them. And they need PMs who understand the product challenges that agents create. Not the engineering challenges. The product challenges.
Here is the core distinction.
A regular LLM call is a one-shot interaction. You send a prompt. You get a response. Done.
An agent is a loop. It receives a goal. It breaks the goal into steps. It executes the first step. It observes the result. It decides what to do next. It keeps looping until the goal is achieved or it determines it cannot proceed.
That loop is where everything gets interesting.
Because an agent makes decisions. Autonomously. Without asking you. It might send an email on your behalf. It might delete a file it considers irrelevant. It might book a flight for the wrong date because it misinterpreted what next Friday means in context.
The technology question is how agents work. Any PM can read a LangChain tutorial and answer that. The product question is much harder and much more valuable in an interview.
How much autonomy should the agent have?
Where do you insert human checkpoints?
When should it ask for permission versus making a judgment call on its own.
How do you design an experience where the user feels in control even though the agent is doing all the work?
Here is the tension that makes this concept so rich for interviews. Users want agents to be autonomous. That is the entire value proposition. Do this for me so I do not have to think about it. But users also want to feel safe. They want confidence that the agent will not do something catastrophic or irreversible.
Speed and safety pull in opposite directions. The PM who can navigate that tension with clear product principles will stand out in every single interview.
The most common mistake candidates make is treating agents as a pure engineering conversation. Talking about function calling, tool schemas and ReAct patterns. That is the implementation layer. Interviewers want the product layer. The experience design. The trust model. The failure recovery flow.
Sample Interview Questions
Q1. You are building an AI agent that helps users book travel. The agent can search flights, compare prices, and make reservations. Design the user experience for when the agent books the wrong dates.
Q2. Your AI agent completes tasks autonomously, but users report feeling out of the loop. How would you redesign the experience to build trust without slowing the agent down?
Q3. An agent-based feature has a 78 per cent task completion rate. Users love it when it works, but are frustrated when it fails. How do you decide whether to ship broadly or keep it in limited access?
5. Guardrails
Here is a question most PMs never think about until it is too late.
What is the worst thing your AI product could do?
Not the most likely failure. The worst. The one that ends up as a screenshot on social media within hours. The one that gets your CEO pulled into a meeting with Legal at 7 am. The one that makes users question whether they should trust anything your product says ever again.
If you have shipped AI in production, you already know this feeling. Because it either already happened to you or you watched it happen to a competitor and thought that could have been us.
Guardrails are how you prevent those moments. They are the systems you build to stop your AI from generating harmful content, leaking private data, producing confidently wrong information, going off topic, or being manipulated by adversarial users who know exactly how to break your system.
Here is why this topic is deceptively difficult.
The naive approach to guardrails is to block everything that looks risky. Restrict the model outputs aggressively. Add filters on every response. Flag anything that seems remotely problematic.
That approach solves the safety problem. It also kills the product. Users start hitting walls on legitimate queries. The AI becomes so cautious it is useless. You have traded one crisis for another. Instead of a harmful output going viral, you have a product that nobody wants to use because it blocks everything.
The real challenge is surgical precision. Block the dangerous outputs. Let the legitimate ones through. Do it fast enough that the user never notices a filter is running behind the scenes.
The layered approach works. Input filters catch bad requests before they reach the model. System prompts constrain the model behavior at the instruction level. Output filters catch problematic responses before they reach the user. Human review handles the edge cases that automated systems miss.
But the product question is always the same. Where do you draw the line.
A guardrail that is too strict blocks 15 percent of legitimate queries and your users leave for a competitor. A guardrail that is too loose lets one harmful response through and your product is trending for the wrong reasons.
That calibration problem is the entire interview. Not what are guardrails. But how do you set them. How do you measure whether they are working. And how do you adjust them when you get it wrong.
Interviewers expect you to go deeper than this.
Sample Interview Questions
Q1. You are launching an AI chatbot for a healthcare company. What guardrails would you implement and how would you prioritise them given a tight launch timeline.
Q2. Users have discovered they can manipulate your AI assistant through indirect prompt injection via pasted text. How do you approach this as a product problem, not just an engineering problem.
Q3. Your guardrails are blocking 12 percent of legitimate user queries. Engineering says tightening the filters further will increase false positives to 18 percent. How do you handle this.
The Pattern You Need to See
Now here is the honest question.
Go back to the 15 sample interview questions in this article. Read them carefully. For each one, ask yourself whether you could give a structured and confident answer that would satisfy a senior interviewer at a top tech company.
If you could answer 12 or more with real depth, you are in strong shape. Keep sharpening.
If you could answer 8 to 11, you have gaps. Targeted gaps. The kind that a focused two-week sprint could close.
If you could answer fewer than 8, the problem is not intelligence. You are smart enough to be reading this article. The problem is exposure.
Nobody has shown you how these concepts actually play out in real product decisions. You have been learning definitions when you should have been practising trade-offs.
That gap is exactly why we built the AI PM course. 800+ PMs have taken it. 4.9 out of 5 rating
The interview has changed. Your preparation should too.
Become an AI Product Builder | 100 Hrs+ Learning
This is not a course you watch passively. It is a program you go through with a cohort of other PMs. You get office hours. You get demo sessions.
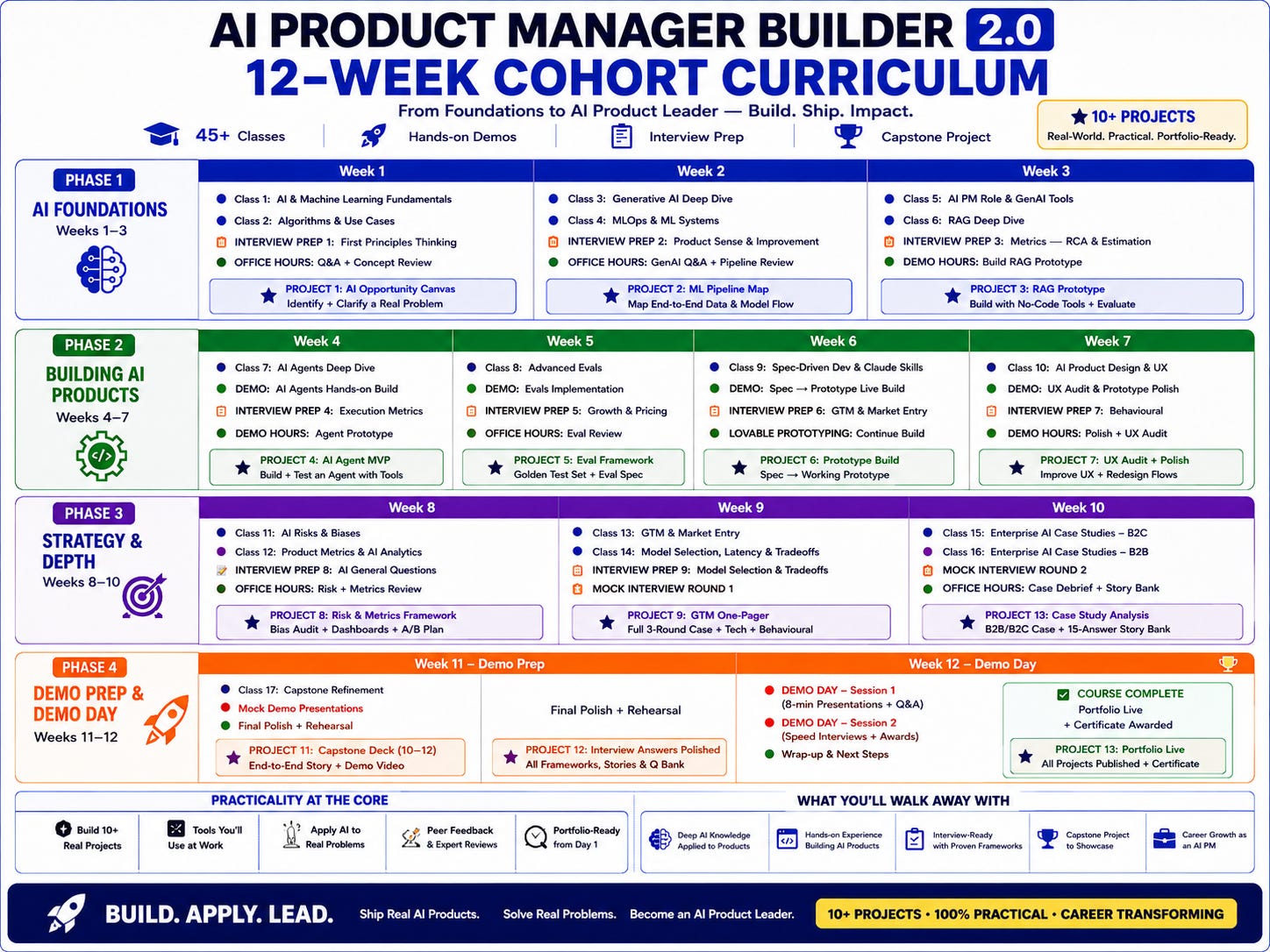
The AI Product Manager Builder 2.0 is a 12-week cohort program. 45 plus classes. Hands-on demos. Interview prep sessions every week. A capstone project. 10+ real-world projects you can add to your portfolio.
About Author
Shailesh Sharma - I help PMs and business leaders excel in Product, Strategy, and AI using First Principles Thinking. Weekly Live Webinars/MasterClass (Here)