
AI PM Interview Question | Design a Deep Research Agent
Step by Step Answer

This question is getting asked a lot by companies recently in the PM Interviews
The interviewer is testing your ability to design a solution and a system around AI.
So in your next Product Management Interview, you might get this, so read carefully.
Let’s try to think about Deep Research Agent from first-principles thinking.
If you want to answer questions like these in depth, you can find out about our flagship AI PM Course (PMs at Microsoft, Google, Coinbase, Indeed & 800+ PMs rated 4.9/ 5).
See testimonials and course details
First, a deep research agent is not a search chatbot
A search chatbot takes one query, pulls a few results, and writes one answer in seconds.
A deep research agent takes one open question, builds a plan, reads dozens to hundreds of sources, works for minutes, and returns a long cited report.
The difference is not scale.
The difference is that the agent decides its own next step. That single property is what changes everything downstream.
The core design problem
Strip it down, and you are running an unbounded search over an unbounded space, on a fixed budget, against a hard reliability bar.
Four hard problems fall out of that framing.
Scoping. Turning a vague question into a bounded investigation.
Stopping. Knowing when the answer is good enough.
Grounding. Keeping the final report tied to real evidence.
Memory. Managing far more content than fits in a single context window.
Every architecture decision you make is a response to one of these four. Keep them in mind as we walk the system.
The architecture
Here is the loop at a glance.
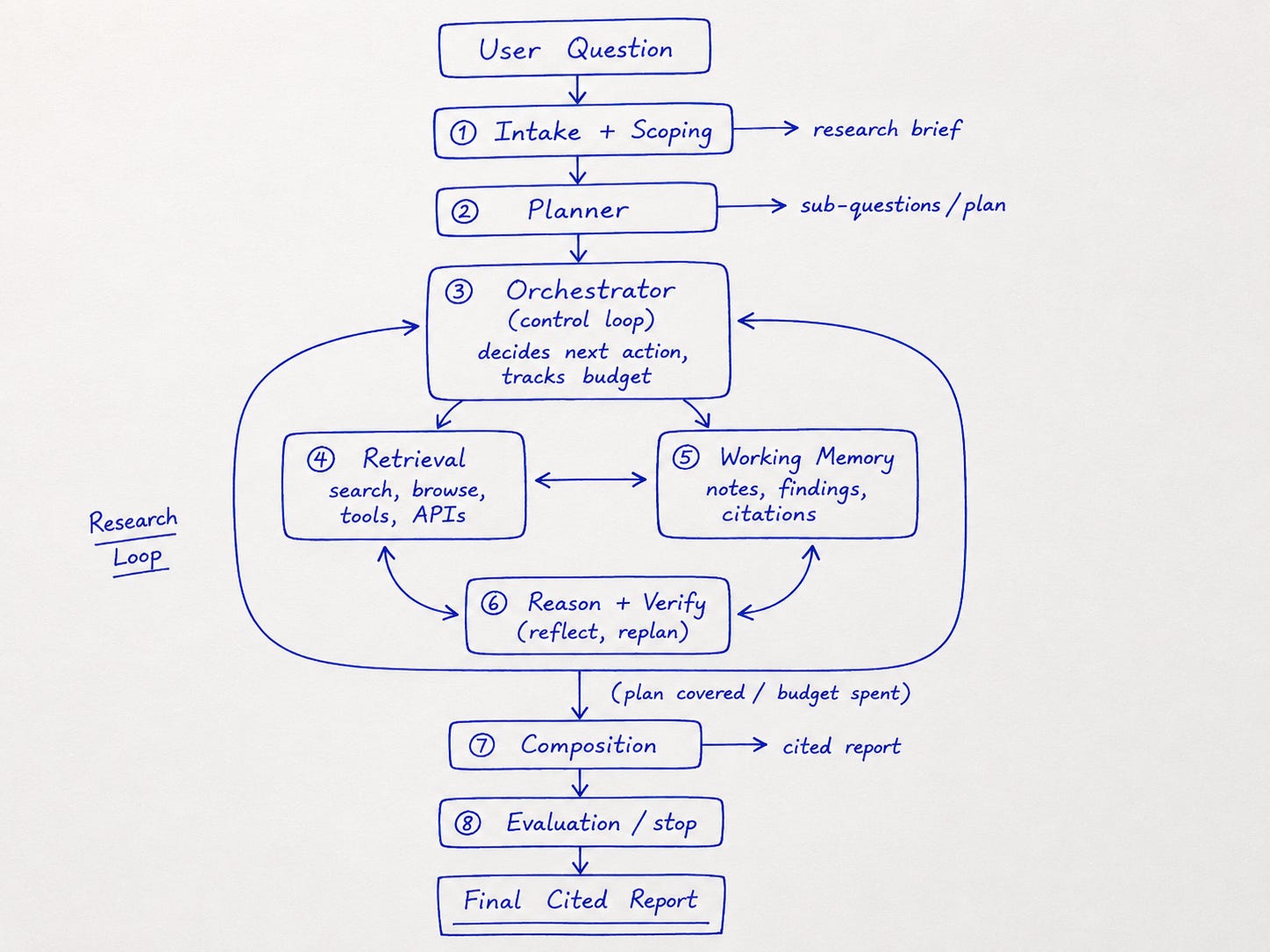
Now the components. For each one, I have added the product decision that sits underneath it, because that is the part a PM actually owns.
1. Intake and scoping
A model pass reads the raw question and turns it into a structured brief.
Goal
Scope
Success criteria
Output format, and what is out of bounds.
If the ask is broad or ambiguous, the agent does not guess. It fires back two or three clarifying questions, then writes the brief. From that point on, the brief is the contract that every later step gets checked against.
The real choice is whether to clarify or infer. Asking first sharply improves scope and adds friction at the same time.
OpenAI’s Deep Research asks. Much of the final quality is decided right here, before a single search runs.
2. Planner
The brief goes to a model that emits a plan.
Usually a list or a shallow tree of sub-questions, each tagged with what to look for and how much effort it deserves.
In practice, this is a structured object the orchestrator can read, not prose. The plan is either fixed for the whole run or revised as evidence arrives, adding a sub-question here and dropping a dead end there.
Static or dynamic is the fork that matters. A fixed plan is cheaper and more predictable. A plan that adapts as the agent learns is where the real quality lives, and where cost and unpredictability creep in.
3. Orchestrator
This is a loop over a state object that holds the plan, the findings so far, and the remaining budget.
Each pass does four things.
Pick the next sub-question.
Choose a tool. Run it.
Write the result back into state.
Then the model looks at the updated state and decides whether to keep going.
It exits when the plan is covered or the budget hits zero.
Budget is the part you cannot skip. Steps, tokens, time, and money are all finite, and without hard ceilings, a single query can quietly cost you ten minutes and several dollars. This is the layer that stops the agent from running away.
4. Retrieval and tools
Search is only the first move. The agent issues a query, gets links, then fetches and reads the full pages, pulls the passages that matter, and follows citations down to primary sources when it needs to.
Tools are handed to the model as callable functions. Search for a query. Fetch a URL. Run code. The model decides which to call and when.
Source quality is what separates a good agent from a fluent liar.
Weigh an SEO farm the same as a primary source, and you get confident nonsense. Treat source trust as a feature you build, not plumbing you inherit.
5. Working memory
The agent reads far more than fits in one context window, so it cannot hold everything at once. It writes as it goes.
A short summary of each source, the exact quotes that matter, and a source ID pinned to each. This lives in an external store, a notes file or a vector index.
At each step, it pulls back only the notes relevant to the current sub-question, and long results are compacted into summaries before they land in the store.
Compaction is the delicate part. Summarise too hard, and you lose the detail that made the source worth reading. Keep too much, and the context bloats and the reasoning degrades. Every long run lives or dies on how well you strike that balance.
6. Reasoning and verification
Gathering and thinking alternate. After each fetch, a model pass interrogates the findings.
Is the sub-question answered?
What is still missing?
Do any two sources disagree?
When a claim is contested or load-bearing, the agent goes and finds a second independent source before it accepts it. The result of this step feeds straight back into the plan, marking a sub-question done or spawning a follow-up.
How hard to verify is the dial you turn. Cross-checking costs extra calls. Skipping it is exactly how confident, unsupported claims slip into the report. This is the trust layer, and trust is the entire product.
7. Composition
A separate writer pass builds the report. It reads the clean findings store, not the messy browsing history, and assembles structure, sections, an executive summary, and inline citations mapped from the claim-to-source pointers collected earlier. Splitting the writer from the researcher lets each do one job well. One is optimised for coverage, the other for clarity.
Resist the urge to research and write in a single call. The output gets noticeably worse when one pass tries to do both.
8. Evaluation and stopping
A final checker holds the report against three things. The plan, to confirm every sub-question was addressed. The sources, to confirm every claim carries a citation. And itself, to catch repetition. Stopping fires on whichever comes first. Full plan coverage, diminishing new information, or an exhausted budget.
Everything here rides on your definition of done. Coverage, groundedness, low redundancy. If you cannot write that definition down, the agent has no way to know when to stop either.
The one fork that defines your product
Single agent, or an orchestrator with subagents.
A single agent is simpler, cheaper, and easier to keep coherent. It struggles with breadth.
An orchestrator that spawns subagents to chase sub-questions in parallel covers far more ground and handles harder questions. Anthropic built its research system this way, with a lead agent directing workers. The cost is real. They reported it burned roughly fifteen times the tokens of a normal chat, and coordinating subagents adds a new class of failure.
There is no correct answer. There is only the answer that fits your question complexity and your unit economics. Pick deliberately.
The North Star Metric?
Number of research reports generated?? North Star??
NO
Because it is an activity metric, not a value metric.
A deep research agent can produce a thousand confident, wrong reports, and the number still goes up. Your North Star should move only when real value is delivered. So value has to be built into the definition itself.
Here is the one I would pick.
North Star. Weekly Trusted Research Tasks. A trusted research task is one the user accepts and acts on without redoing the work themselves.
Two words carry the weight.
Trusted means the output earned action.
Weekly means we are tracking a habit, not a one-time trial.
Volume lives in the count. Quality lives in the word trusted. A good North Star should be impossible to move by gaming a single dimension. This one clears that bar.
Question. Should time saved be the North Star instead?
Tempting, because saving time is the real benefit. But time saved is hard to measure honestly, and it is a downstream effect of trust and quality. Report it as a headline outcome. Do not steer by it.
Breaking it into components
A North Star you cannot decompose is a slogan. Here is the decomposition into three components.
Weekly Trusted Research Tasks = Active Researchers(who) X Tasks per Researcher(how often) X Trust Rate(how good)
Each component has a literal meaning and a physical meaning. The physical meaning is what matters, because it tells you what real-world force you are actually measuring.
Active Researchers: Literally, people who ran at least one real research task this week. Physically, this is a demand. It is the market deciding whether your agent is worth bringing a real question to.
Tasks per Researcher: It measures whether the agent has embedded into how someone works, or whether it was a novelty they tried once.
Trust Rate: It is the only component that captures quality, and it is the one most teams forget to instrument.
Multiply the three, and you get value delivered. Move any one of them, and the North Star moves for an honest reason.
Failure modes to design against
Scope drift, where it answers a slightly different question than the one asked.
Shallow breadth or narrow depth are the two ways a plan can be wrong.
Low-quality sources echoed as fact.
Hallucinated citations that point to real pages that do not support the claim.
Context rot, where the agent loses the thread across a long run.
Most of these trace back to the four core problems. Scoping, stopping, grounding, memory. If your design has a clear answer for each, you have handled most of the list.
If this is the muscle you want to build, there are two ways I can help, and they are different things.
The AI PM Builder Cohort is the deep end. A small group builds systems like this live, over twelve weeks. Real agents, real evals, real portfolio work you can show. If building beats reading for you, that is the room to be in.
About Author
Shailesh Sharma! I help PMs and business leaders excel in Product, Strategy, and AI using First Principles Thinking. AI Product Manager/Builder Cohort
More Resources
Product Management Mock Interview (Detailed)
Crack AI Business Roles (AI Management Consulting, AI Category Management, AI General Manager, Revenue Planning, etc.) - Course Details
Crack AI Program Manager Roles - Course Details