
How would you measure the success of RAG?
First Principle Breakdown


Imagine you are sitting in a product manager (PM) interview and the interviewer asks a question.
He asks how you would measure the success of the RAG (Retrieval Augmented Generation) system, which they have used in their new AI shopping assistant.
If you start talking about traditional metrics, you might fail the interview right there.
This is because in the world of Retrieval Augmented Generation, these metrics can be very deceptive.
A user might spend twenty minutes talking to a bot not because they love it but because the bot is giving wrong information and they are trying to correct it.
This article will help you understand RAG success through first principles so you can answer such questions with confidence.
BTW, we have our course where we teach about the Metrics for Agentic Systems, Multi Agentic workflow etc , these questions are rising rapidly.
Why Traditional Metrics are Deceptive
If a customer has to ask five follow-up questions to find a simple return policy, then your system has failed, even if your session length looks high.
You cannot measure a RAG system like a social media app. You have to measure it like a precision tool. The goal is not to keep the user on the chat but to give the correct answer as fast as possible.
The First Principles of RAG Success
To understand how to measure success, you must break the system down into its two core engines.
First is the retriever which is responsible for finding the right product data from your catalog.
Second is the generator which is the AI model that writes the answer based on that data.
You can think of the overall success of your product as a simple mathematical multiplication.
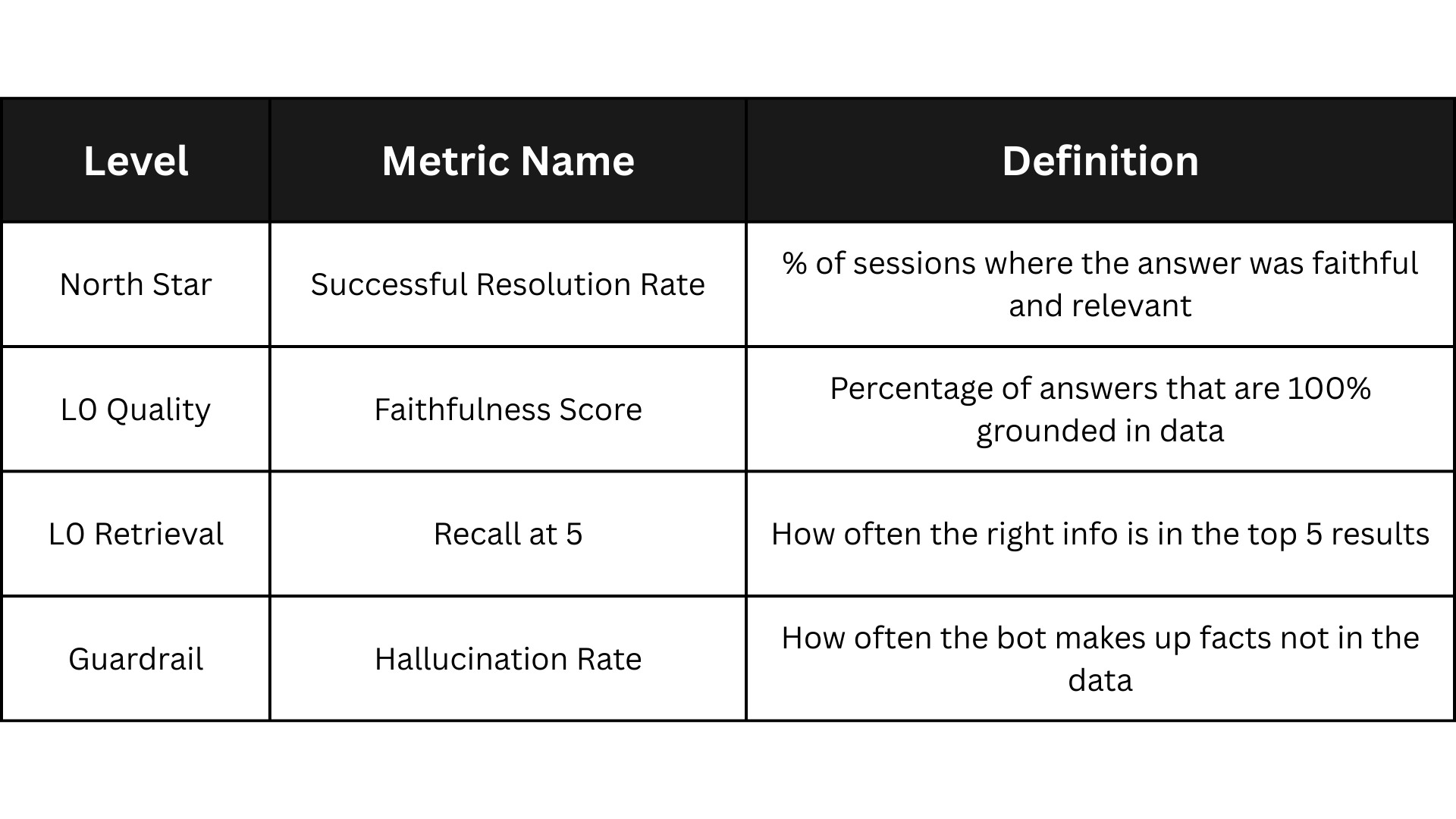
Success = Retrieval x Generation
If the retriever fails to find the correct product then the generator has nothing to work with and the success is zero.
If the retriever finds the right data but the generator lies about the price or features then the success is still zero. You must measure both parts separately to find out where your product is breaking.
Measuring the success of Retriever
In ecommerce you need to know if the bot is actually seeing the right products from your database.
Recall @k
Recall at k is one of the most important metrics here.
It checks if the correct product or information is present anywhere in the top k results retrieved. If the answer is in your database but your search does not find it in the top five or ten results, then the AI is effectively blind to that information.
Precision @k
Precision at k measures how much noise you are feeding to the AI. If you pull ten documents and only one is relevant then your precision is low. Feeding too much irrelevant data to an AI can make it confused and lead to a wrong answer.
Mean Reciprocal Rank or MRR tells you how high up the first relevant result is. In ecommerce you always want the best match at the very top. If the right product is consistently at the bottom of your search results then your ranking logic needs work.
Measuring the success of Generator
Once you know your search is working you must ensure the AI is not making things up or being unhelpful.
Faithfulness or Groundedness is the most critical metric for trust.
It checks if the final answer stays true to the facts found in the retrieved data.
If the product manual says a phone has a five thousand mAh battery but the AI says it lasts for two days without mentioning the capacity it might be a risk. If it says six thousand mAh then it has failed the faithfulness test completely.
Answer Relevancy measures if the AI actually addressed the specific thing the user asked. It ensures the bot does not give a generic sales pitch when the customer asked a technical question about compatibility.
Context Recall checks if the AI used all the necessary facts provided by the retriever. If your search found three different features that the user asked for but the AI only mentioned one then the answer is incomplete even if it is factually correct.
How to Evaluate at Scale
You cannot manually read every single chat to give these scores.
The professional way to do this is using a technique called AI/LLM as a judge.
You take a LLM model like GPT 5 / Gemini 3 and give it the original question along with the facts found and the final answer created by your bot.
The judge model then uses specific rubrics to give a score for faithfulness and relevancy. This allows you to test hundreds of questions in minutes and see exactly which part of your engine is failing.
Imagine now you have gotten a next question in an Interview like
“How would you measure the success of a Multi Agentic System?” - If you want to learn how to answer using first principle thinking, you can find it here.
If you like this article, you will absolutely love our Course ( having real AI PM Interview Questions ( Details Below )
Most Detailed AI Product Management Course ( Along with AI PM Interview Questions )

For New Year, we are giving EXTRA 60% OFF on our AI PM Flagship Course for very limited Time
Coupon Code — NYE26 , Course Link - Click Here
Shailesh Sharma! I help PMs and business leaders excel in Product, Strategy, and AI using First Principles Thinking. For more, check out my AI Product Management Course, PM Interview Mastery Course, Cracking Strategy, and other Resources
 | A guest post by
|
Thanks, this clarifies a lot. What if long engagemen is really just frustration?