
The Model Choice Playbook Every AI PM Needs in 2026
AI Model Selection Framework

AI Model Selection has become a very critical skill and getting asked in a Lot of Interviews
Imagine your CEO asks you to build an AI customer support agent for a food delivery app that handles 2 million tickets a month.
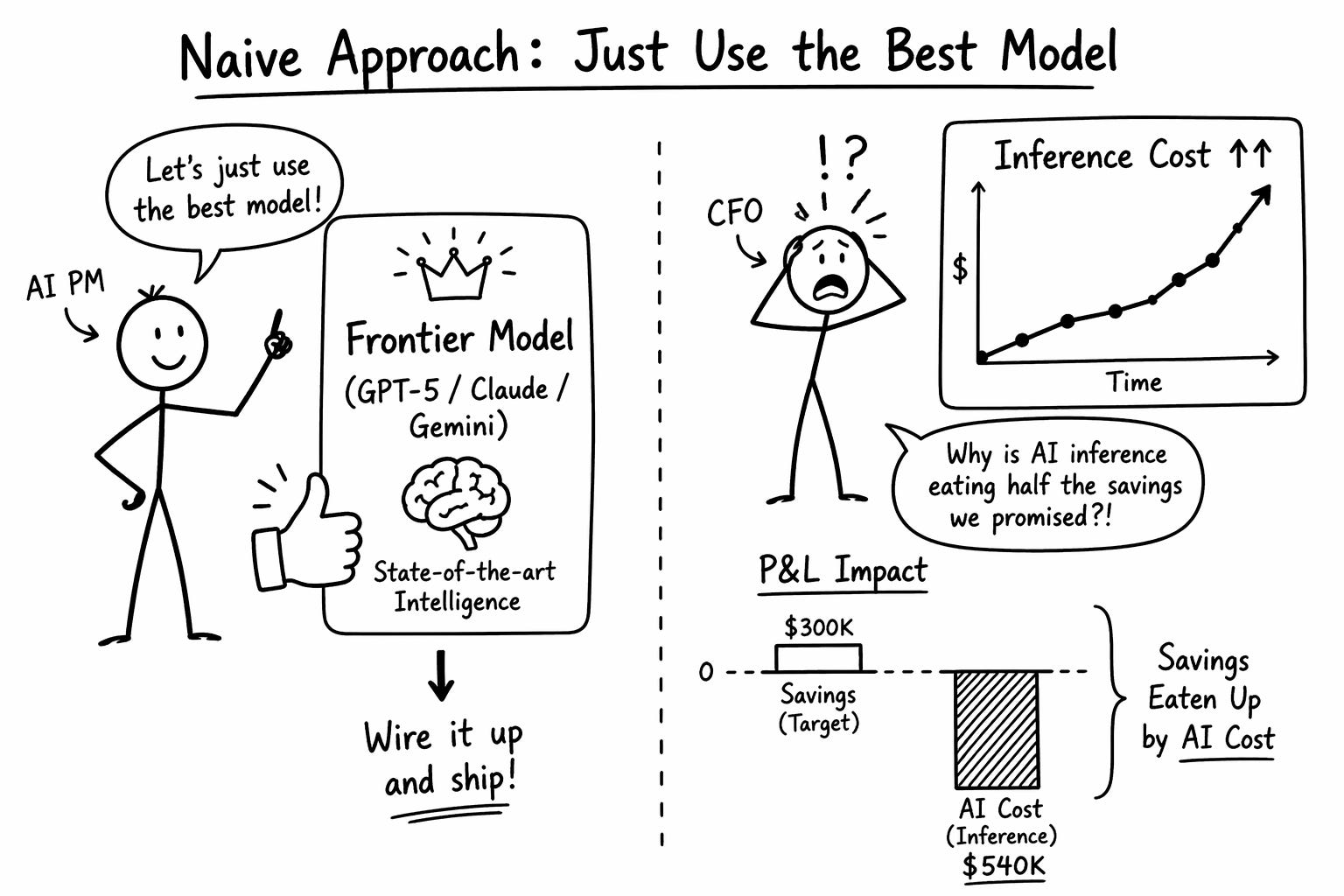
You think that Just use the best model. GPT-5. Claude Opus. Gemini 3, wire it up, and ship it.
You do the math, and you realise the ROI will not make sense.
If your instinct as an AI PM is to default to the frontier model on the leaderboard, you will ship a product that wins the pilot and loses the P&L.
Your agent will feel smart. Your margin will turn negative. Your CFO will ask why AI inference is eating half the savings you promised.
This is the first-principles breakdown of how AI PMs should actually make model-choice decisions. We will walk through it using one real scenario.
Building an AI customer support agent for a food delivery app at the Swiggy or DoorDash scale.
If you are preparing for AI PM interviews, this is one of the questions that now separates real AI PMs from people who have only used ChatGPT. You can check out other AI PM Interview Questions here.
The Scenario
You are the AI PM at a food delivery company.
You have 2 million support tickets a month. Human agents currently handle them at roughly 0.5$/ticket. Total support cost is 1 million dollars a month.
Your CEO gives you a mandate. Cut that by 70% with an AI agent.
The ticket distribution looks like this.
50% ~ Where is my order?
20% ~ missing items or cold food.
15% ~ are refund disputes.
10% ~ are restaurant quality complaints.
5% ~ are complex multi-turn escalations involving payment failures, account issues, or angry users demanding managers.
Some tickets take three seconds to resolve. Some take a thirty-turn conversation. Some require reading six previous tickets to understand what the user is asking. Some are hungry users at 10 PM typing in all caps.
The naive answer is to wire up a frontier model and pipe every ticket through it.
Let us see what happens when you do this.
What is Model Choice, Really?
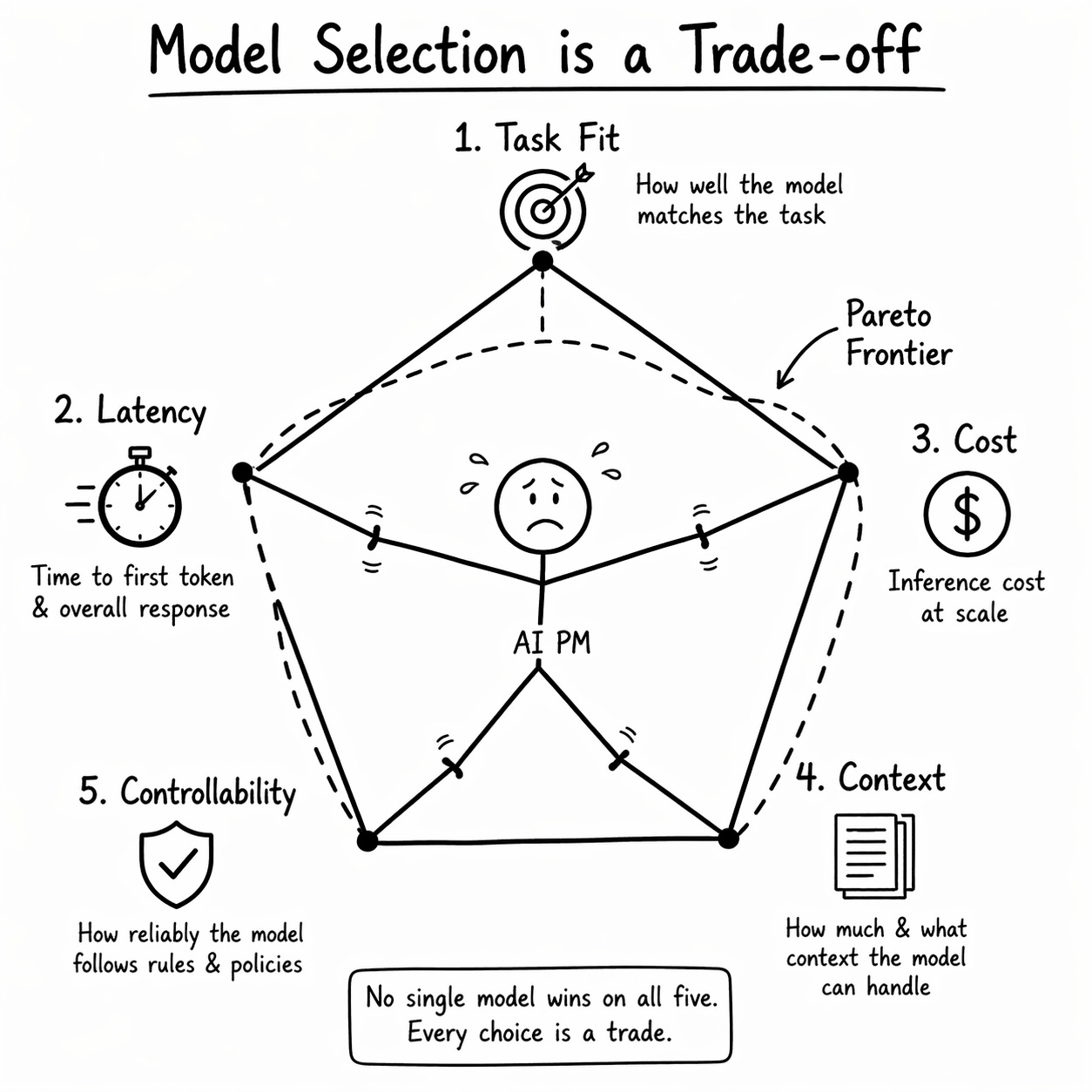
Model choice is not a vendor decision. It is a five-dimensional optimisation problem under a hard business constraint.
You are picking a point on a Pareto frontier defined by Task Fit, Latency, Cost, Context, and Controllability. No single model wins on all five. Every choice is a trade.
For this support agent, the trade is complicated.
If you use a frontier model for every ticket. Quality is high.
At two million tickets of an average 5 turn conversation, at roughly 0.27$ of inference per ticket, you spend 540,000 dollars a month. You have already burned 54% of the savings you were hired to deliver. Add infrastructure, monitoring, safety guardrails, and retries, and you are above 70%.
If you use a cheap model for every ticket. Cost is fine.
But the model hallucinates refund policies, misreads Hinglish, and escalates half your tickets to humans anyway. Your deflection rate drops from 70% to 30%. The math collapses from the other direction.
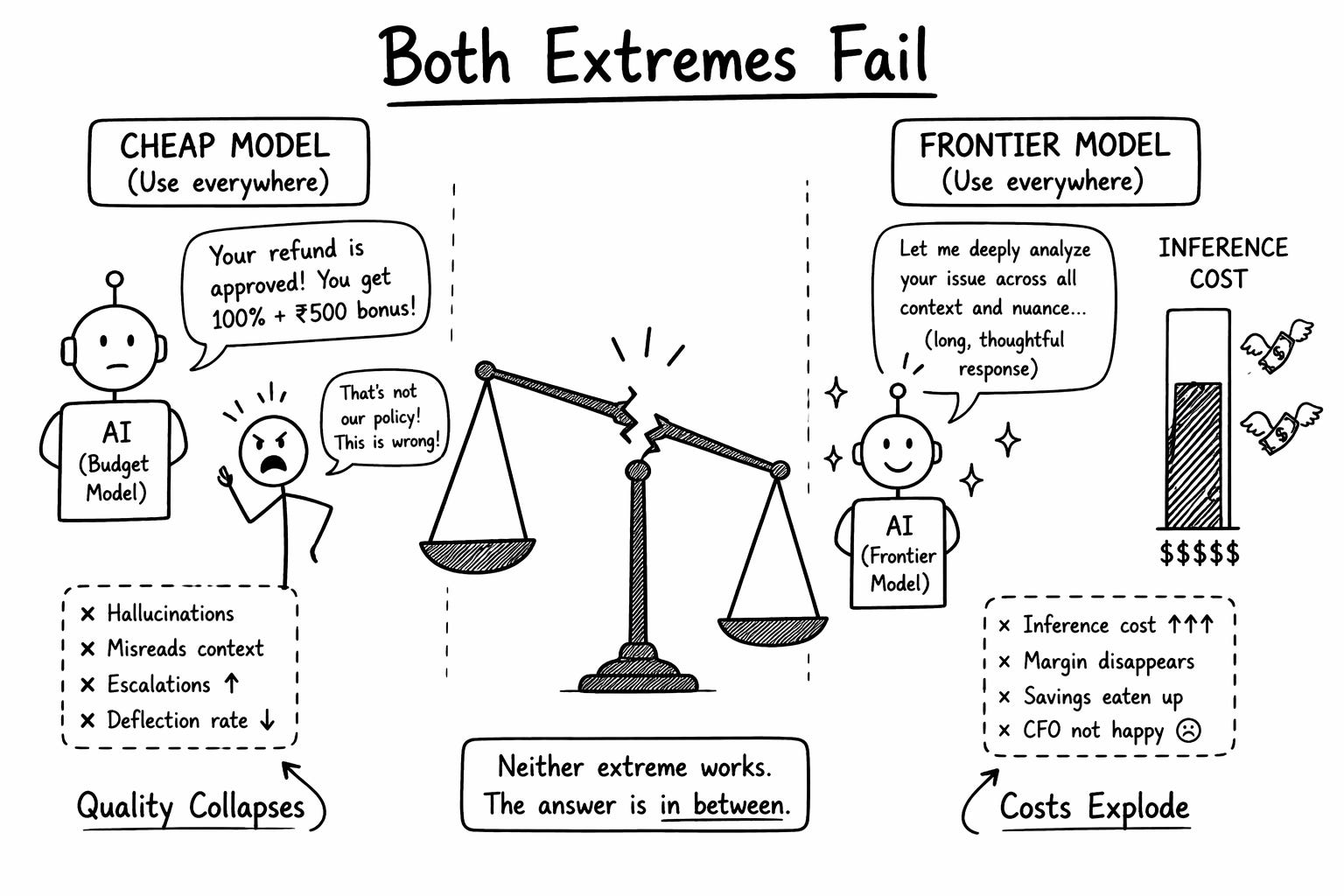
Neither extreme works. The right answer lives in between. The PM decides where.
The Strategic Bet
Here is what most PMs miss entirely.
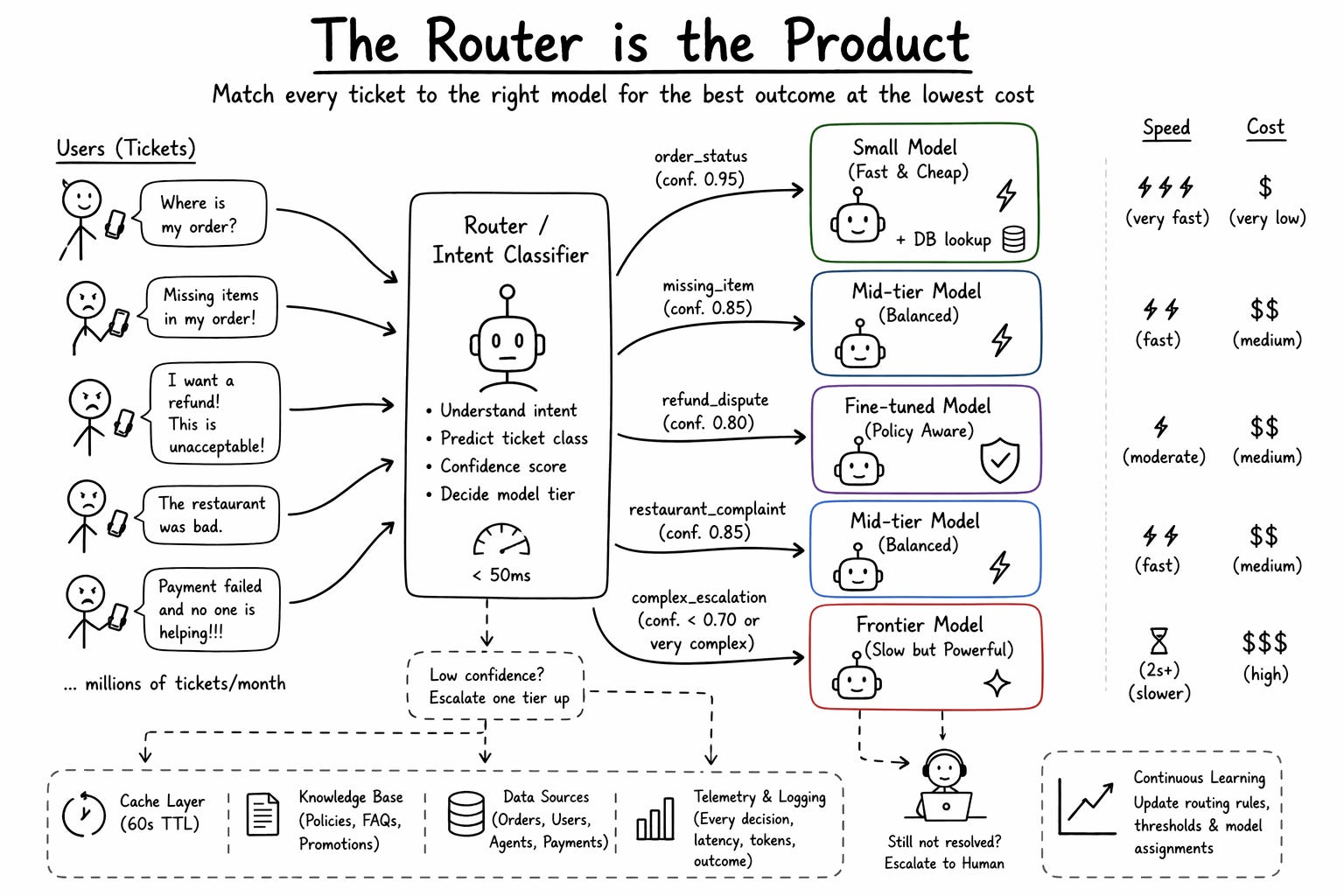
The support agent you are about to build does not run on a single model. It runs on a routing layer that decides which model handles which ticket.
—> Where is my order needs a database lookup, a tiny model to format the response, and a sub-500ms latency target.
—> A refund dispute from an angry user who has already had three bad experiences needs a frontier model, long context, and two seconds of real reasoning.
Shoving both requests into the same model is how you lose money and lose users at the same time.
The router is where your actual product intelligence lives. It is the layer that turns commodity foundation models into a profitable support operation.
Anyone can call the OpenAI or Anthropic API. What no competitor can easily copy is your 18 months of telemetry about which ticket class wins on which model at what confidence threshold with your specific users.
So the Problem Statement becomes - How do we match every incoming ticket to the cheapest model that still clears the user’s quality bar, within our latency SLA, at a positive contribution margin against human support cost?
Over-routing to the expensive model and inference eats the savings. Over-route to the cheap model and deflection collapses because humans have to clean up after the agent.
The Five Constraints
Before you pick a model, you score every candidate on five constraints. Most PMs only think about one or two.
Constraint 1: Task Fit
Task Fit measures how closely the model’s training matches the actual ticket.
Where is my order is not a reasoning task. It is a structured data lookup wrapped in natural language.
A small model paired with a database call beats a frontier model here. The frontier model writes more than needed, invents delivery estimates, and hedges unnecessarily.
A refund dispute is a reasoning task. The user references past tickets, implies context, negotiates, and escalates. A small model collapses. You need the frontier model.
The same agent handles both. Task Fit tells you they cannot be handled by the same model.
The only way to score Task Fit honestly is to build an internal eval set.
200 real tickets, sampled proportionally across ticket types. Every candidate model runs through it. A human or a judge model rates outputs on a rubric. This eval set is owned by the PM, not the ML team, and it is refreshed every month with real production data.
Constraint 2: Latency
Time to first token is what the user feels when they hit send.
For the 50% of tickets that are order status lookups, your target is under 500ms. The user is anxious. Every extra second is another 10% chance they open Twitter instead.
For the 5% of complex escalations, 2 seconds is acceptable if the response is visibly thoughtful. The user is already in a serious conversation and expects weight.
Your router itself has a latency budget. If your intent classifier takes 300ms to decide where to send the ticket, you have already burned most of the user’s budget before the actual model has started generating.
This is why classifier models are almost always small, often distilled or fine-tuned, tuned to run under 50ms. The router cannot be the bottleneck.
Constraint 3: Cost
At 2 million tickets a month, run the math on frontier-only inference.
Average ticket: five turns, roughly 2,000 accumulated input tokens per turn and 400 output tokens. At frontier model prices of roughly 15 dollars per million input tokens and 60 dollars per million output tokens, one ticket costs about 0.27$.
2 million tickets a month at 0.27$ each is 540,000 dollars in pure inference.
Your human baseline was 1 million dollars. Your AI inference alone is 54% of that. Your CEO is not impressed.
Now run the same math with a routed system.
70% of tickets go to a cheap model at $0.01 each.
25% go to a mid-tier at $0.08.
5% go to the frontier model at $0.27.
Weighted average lands at 0.04$ per ticket. Total monthly inference cost: 81K
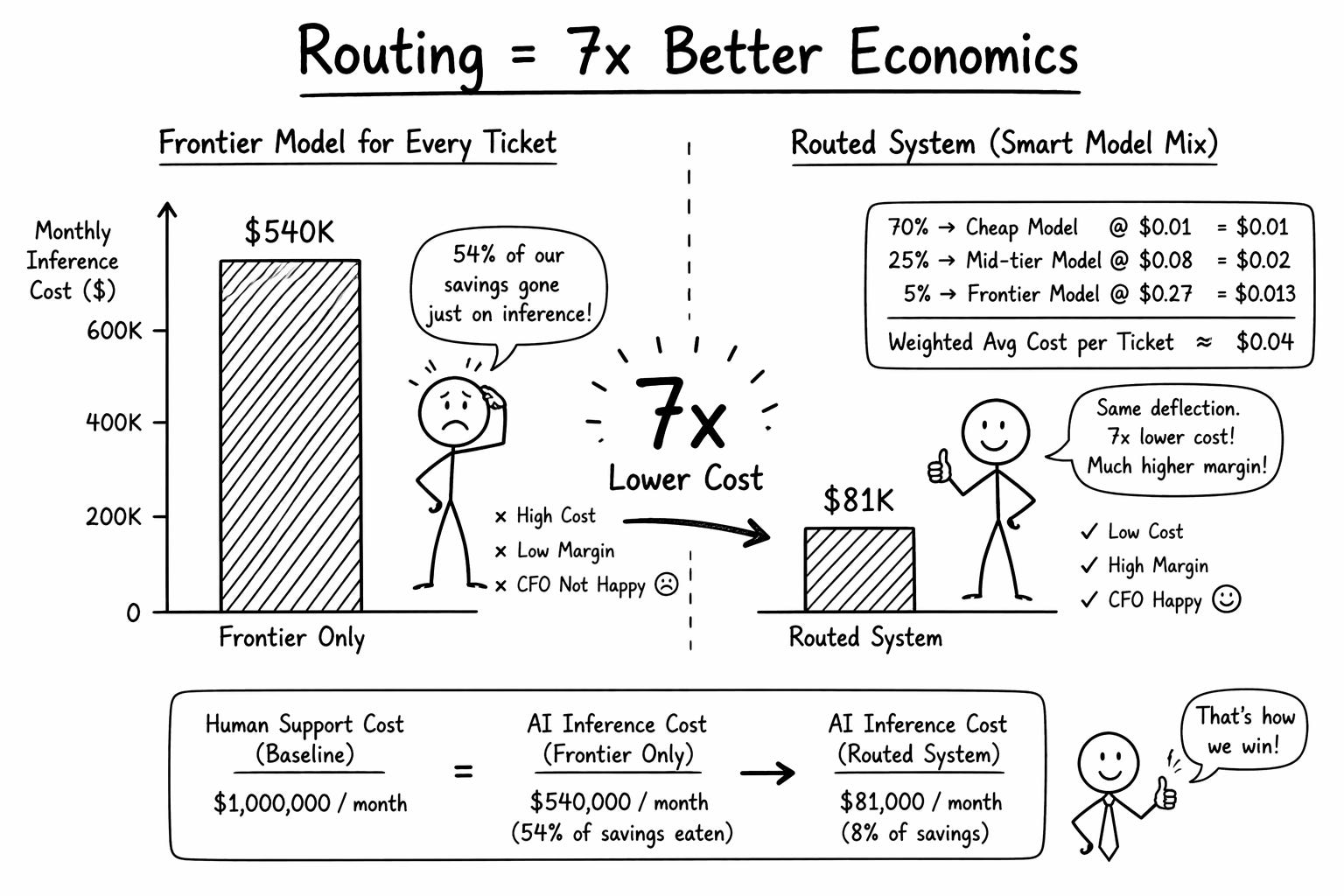
Same deflection rate. Nearly 7x the margin.
Constraint 4: Context and Memory
The agent needs context like past orders. previous tickets from the same user, restaurant policies, active promotions, delivery agent notes etc.
The instinct is to stuff everything into a 200K context window and let the model figure it out. This fails in two ways.
Models measurably degrade past a certain context length, usually between 30K and 100K tokens, depending on the model. This is the lost-in-the-middle problem, and it is real.
Cost scales with every token included on every turn across millions of tickets. A 50K context blindly passed every turn turns your 0.04$ ticket into a $0.25 ticket. You have rebuilt the frontier-only problem with extra steps.
The right answer is retrieval. Pull only the relevant past order, the specific restaurant’s policy, the last two tickets, and the user’s LTV tier. Keep the context under 4,000 tokens. Let the router decide when a ticket is complex enough to justify pulling the full history.
Retrieval gives you control. Massive context gives you a black box that silently gets worse and more expensive as you fill it.
Constraint 5: Controllability
A customer support model cannot invent a refund policy.
If the model says you will get a full refund plus 500 rupees credit and that is not your policy, you have two problems. You either honour the invention and bleed money. Or you refuse and face a Twitter escalation.
Controllability is how reliably the model sticks to your rules under adversarial inputs.
Frontier models are generally more capable but not always more controllable. A fine-tuned, smaller model trained on your exact refund policy will follow the rules more reliably than a frontier model with a clever prompt. For the 15% of tickets that are refund disputes, controllability beats raw capability.
Most PMs stop at the first two constraints. The best AI PMs score every candidate on all five, document the trade, and revisit the scorecard every quarter.
Why - Just Use the Best Model - Fails Here
The argument is familiar. LLM Prices are dropping or will drop drastically in future. Capability is doubling. Just pick the top model and wait.
Three reasons this is wrong for the support agent.
Your competitor is not waiting. If they run a routed system today, they save 450K $ a month and reinvest it into faster delivery SLAs or cheaper customer acquisition. By the time frontier prices drop, they have already eaten your growth.
Best is relative to the ticket class, not the benchmark. The frontier model loses to a fine-tuned, smaller model on structured refund queries.
Cost drops do not flow to users. Every time inference gets cheaper, users expect richer responses, longer context, and more autonomy. If your unit economics are bad today, they are still bad tomorrow on a cheaper, more capable model.
Betting on the best model is a tax you pay to avoid doing the actual PM work.
The Router Pattern, Built for the Agent
Your router has five components.
An intent classifier sits in front of every ticket. A small fine-tuned model, under 50ms. It reads the ticket and returns one of five labels. order_status, missing_item, refund_dispute, restaurant_complaint, complex_escalation. It also returns a confidence score.
A model assignment table. order_status goes to a small model plus a database call. missing_item goes to a mid-tier model with a template response. refund_dispute goes to a fine-tuned, smaller model trained on your refund policy. restaurant_complaint goes to the mid-tier. Complex escalation goes to the frontier model.
A confidence threshold. If the classifier returns low confidence, the ticket escalates one tier up. If the primary model returns a low-confidence answer or the user replies “this is wrong”, it escalates again. The third escalation goes to a human.
A cache layer. 40% of “where is my order” tickets in a one-hour window ask about the same handful of delayed orders in a single city. Cache the response per order ID with a 60-second TTL. Zero inference cost on a cache hit.
A telemetry layer. Every ticket logs the classifier label, model chosen, tokens consumed, latency, user reaction, and final disposition. This is where your routing intelligence compounds.
The sophistication is not in the components. It is in the ongoing tuning of the assignment table based on telemetry.
One Ticket, End to End
Follow a single ticket through the router.
A user types “bhai order kidhar hai, 45 min ho gaye” at 9:47 PM.
The ticket hits the edge. It is hashed and checked against the cache. No hit.
It goes to the intent classifier. Classifier returns order_status, confidence 0.93. 42 milliseconds elapsed.
The router looks up the assignment table. order_status with high confidence goes to the small model plus a database call.
In parallel, the system pulls the user’s active order and the delivery agent’s current GPS location. 80 milliseconds.
The small model receives the ticket plus structured context. It generates “Your order is 4 minutes away. The delivery agent is on the last stretch”. Time to first token: 210ms. Total response time: 480ms.
Telemetry logs the full trace. Ticket class, model used, tokens consumed, latency, user’s next message.
The user replies “ok thanks”. Telemetry marks this as a positive resolution.
The router chose the right model. The user got a fast answer. The ticket cost you $0.004 against a human cost of $0.5. Multiply by one million similar tickets a month, and you see where the money is actually saved.
That is the product.
Model choice is where the business is either made or broken. And it is the PM’s job to decide.
If this article changed how you think about model choice and AI product strategy, you will find much more depth in our AI PM course. We cover model selection, routing architectures, AI evals, cost modelling, and real interview questions from top companies.
Check our highest-rated AI PM course (Including AI PM Interview Preparation) · 4.9/5 · 600+ enrollments → See testimonials and course details
About Author
Shailesh Sharma! I help PMs and business leaders excel in Product, Strategy, and AI using First Principles Thinking. Weekly Live Webinars/MasterClass ( Here )