
Memory in AI — Part 2
How Instagram decides what to remember?


In Part 1, we established the core equation. If you haven;t read the article, please click here
Context × Reasoning × Memory = Perceived Intelligence
We named four memory types. In-context. External. In-weights. KV Cache.
But naming them is not the hard part.
The hard part is this: which memory type do you use, for which feature, and why?
That is what Part 2 answers. And we will answer it using a product your users open fifteen times a day — Instagram.
Instagram is not a single product.
It is a bundle of features, each with a different job, each running a different memory strategy — sometimes on the same screen.
Open Instagram right now. You will find:
Reels — a feed that knows exactly what keeps you watching
Meta AI — a conversational assistant built into the search bar and DMs
Explore — a discovery surface that learns your taste over time
Each of these features has a different answer to the same question: what should the AI know about you, and when should it know it?
Most PMs look at these as three different features.
The right way to look at them is as three different memory architectures producing three different product outcomes.
Let’s discuss Meta AI on Instagram
When you type a message into Meta AI inside Instagram, four memory systems activate simultaneously. Most users see none of this, and most PMs don’t either.
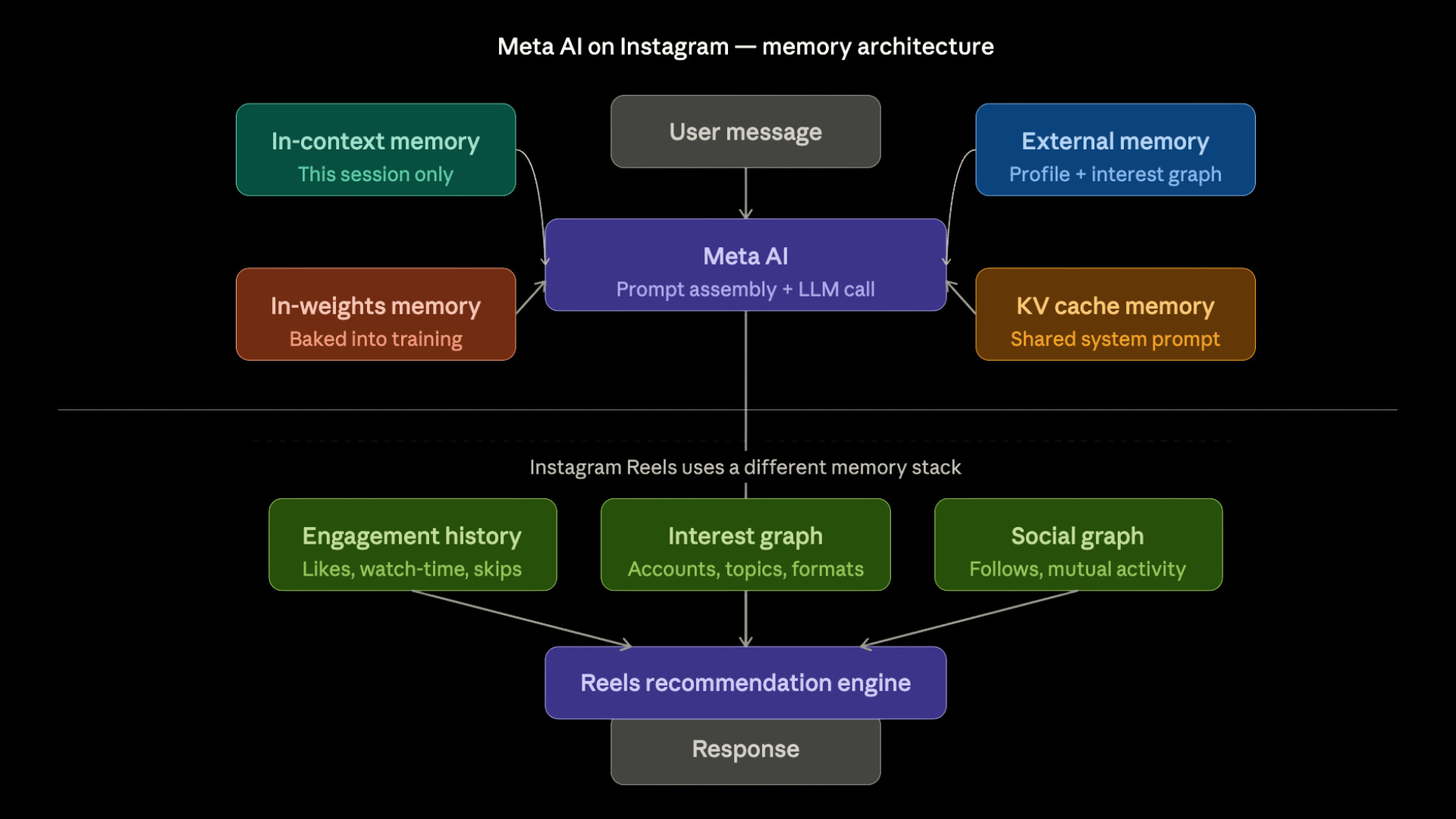
In Context Memory
In-context memory handles everything in the current conversation. Your message. Meta AI’s reply. The follow-up question you ask three messages later. All of it lives in a single context window for the duration of that session. When you close the chat, it is gone.
In Weight Memory
In-weights memory is the foundation. Meta AI’s base model was trained on billions of documents. It knows what pasta is. It knows the difference between a North Indian restaurant and a Italian restaurant. It understands that something exciting for a Friday night means something different in Bangalore than it does in Paris. None of that required you to explain it. It is baked into the model’s parameters from training.
External Memory
External memory is where it gets interesting. When you ask Meta AI for restaurant recommendations in your city, it does not guess. It retrieves. Meta’s interest graph — built from your likes, saves, follows, watch history, and search patterns — gets injected into the prompt before the model responds. The model did not learn your preferences. It looked them up.
KV Cache Memory
KV cache memory is invisible to you but critical to Meta’s infrastructure. The system prompt that tells Meta AI how to behave — its tone, its safety rules, its persona guidelines — is the same across hundreds of millions of user sessions. Rather than re-processing that system prompt from scratch for every conversation, the model’s intermediate computations are cached and reused. This is not a product feature. It is a cost and latency optimisation. But at Meta’s scale, it is what makes the economics work.
Now look at Reels — a completely different memory stack
Reels does not have a context window problem.
It does not forget you when you close the app. It does not start from zero when you open it again tomorrow.
That is because Reels does not use in-context memory at all.
Everything Reels knows about you lives in external memory — a continuously updated store of your engagement signals.
Every video you watch to completion is a signal. Every video you skip after two seconds is a signal. Every creator you follow, every sound you save, every comment you leave — all of it writes into an external memory store that the recommendation engine reads from the moment you open the app.
This is why Reels feels more intelligent over time than Meta AI does. It is not because the recommendation model is smarter than the language model. It is because Reels was architected with persistent external memory, and Meta AI largely was not.
The Goldfish Problem from Part 1? Reels solved it. Meta AI has not.
The PM decision framework: Memory Fit Matrix
So how do you decide which memory type to use for a given feature? Here is the framework.
Ask three questions about each piece of information your feature needs to work well.
How often does it change?
Information that changes every message belongs in in-context memory. Information that changes over weeks or months belongs in external memory. Information that almost never changes can be baked into the model via fine-tuning.Is it shared across users or specific to one user?
A system prompt is shared. Your interest graph is not. Shared, stable information is a candidate for KV caching. Personalised, dynamic information needs external retrieval.What breaks if you get it wrong?
If you stuff the wrong information into the in-weights memory through premature fine-tuning, you cannot fix it without a full retraining cycle. If you miss something in in-context memory, the damage is limited to that session. The higher the cost of being wrong, the more you want the information in an editable, retrievable external store rather than baked into weights.
A PM who understands this will make better architectural calls than one who only asks can we use RAG for this?
If this framing changed how you think about AI product design, and if you want the full structured path — from AI foundations to RAG, Evals, AI strategy, and interview prep — built specifically for PMs, that is what our course covers.
Highest rated AI PM course · 4.9/5 · 500+ enrollments → See testimonials and course details 60% OFF for a limited time — Code: NYE26
About Author
Shailesh Sharma! I help PMs and business leaders excel in Product, Strategy, and AI using First Principles Thinking. For more, check out my AI Product Management Course, PM Interview Mastery Course, Cracking Strategy, and other Resources
 | A guest post by
|