
Why Your Recommender Keeps Forgetting You?
AI Product Management Case Study


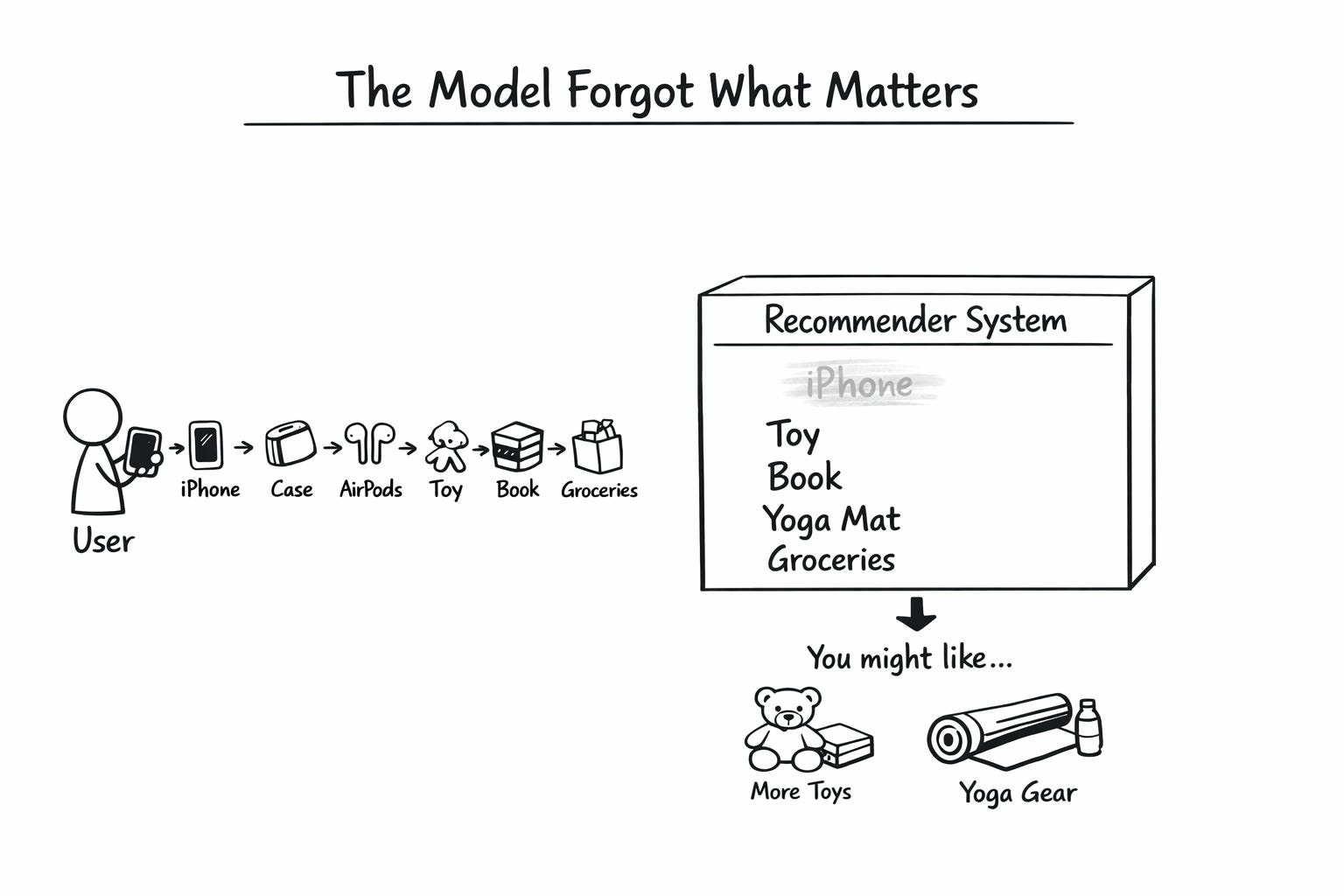
Imagine this, you buy an iPhone on Amazon.
Three days later, you buy a case for it. A week after that, you buy AirPods. Normal journey.
Your recommendation feed is doing its job.
Then life happens. You buy a birthday gift for your niece. A toy. Then a book for your dad. Then a yoga mat. Then some groceries.
Now you come back looking for a screen protector for that iPhone.
Here is the problem. Your recommender has forgotten about the iPhone.
The model remembers what you did most recently.
Toy. Book. Yoga mat. Groceries.
Based on that, it is now quietly convinced you are a gifting parent with a wellness streak. It is showing you more toys, more books, more yoga equipment.
Meanwhile, the single most important signal about what you want right now, the iPhone from three weeks ago, has been washed out.
This is not a theoretical problem. This is happening on most recommendation systems you use today.
Today, we are going to see how to fix that.
In our previous piece, we explained how TikTok uses session-based RNNs to predict your next swipe. At the end, we flagged three pitfalls. One of them was Catastrophic Forgetting. This article is a deep dive into the paper that solved it.
If you are preparing for AI PM interviews, recommendation system design is the most commonly asked system design topic at senior levels. We teach this in our course.
The iPhone Problem
Let us go back to your Amazon story. Why did the model forget the iPhone?
The reason lies in how most recommenders store your history.
An RNN-based recommender works like this. Every time you buy something, the model converts that item into a short numerical fingerprint. Then it mixes that fingerprint into a single vector called the hidden state. One vector. That is the model’s entire memory of you.
Think of the hidden state like a single sticky note. Every time you buy something, the model scribbles on that same note, and whatever was written before gets slightly smudged.
After your iPhone purchase, the note says “wants tech accessories.”
After the case and AirPods, it still says roughly that.
Then you buy a toy. The note gets rewritten. Now it says “tech accessories and a gift.”
Then a book. Yoga mat. Groceries. By the time you come back for that screen protector, the sticky note no longer mentions the iPhone at all. It says something like “parent on a wellness kick with household needs.”
The iPhone signal is not lost. It is buried. Smeared under four unrelated purchases.
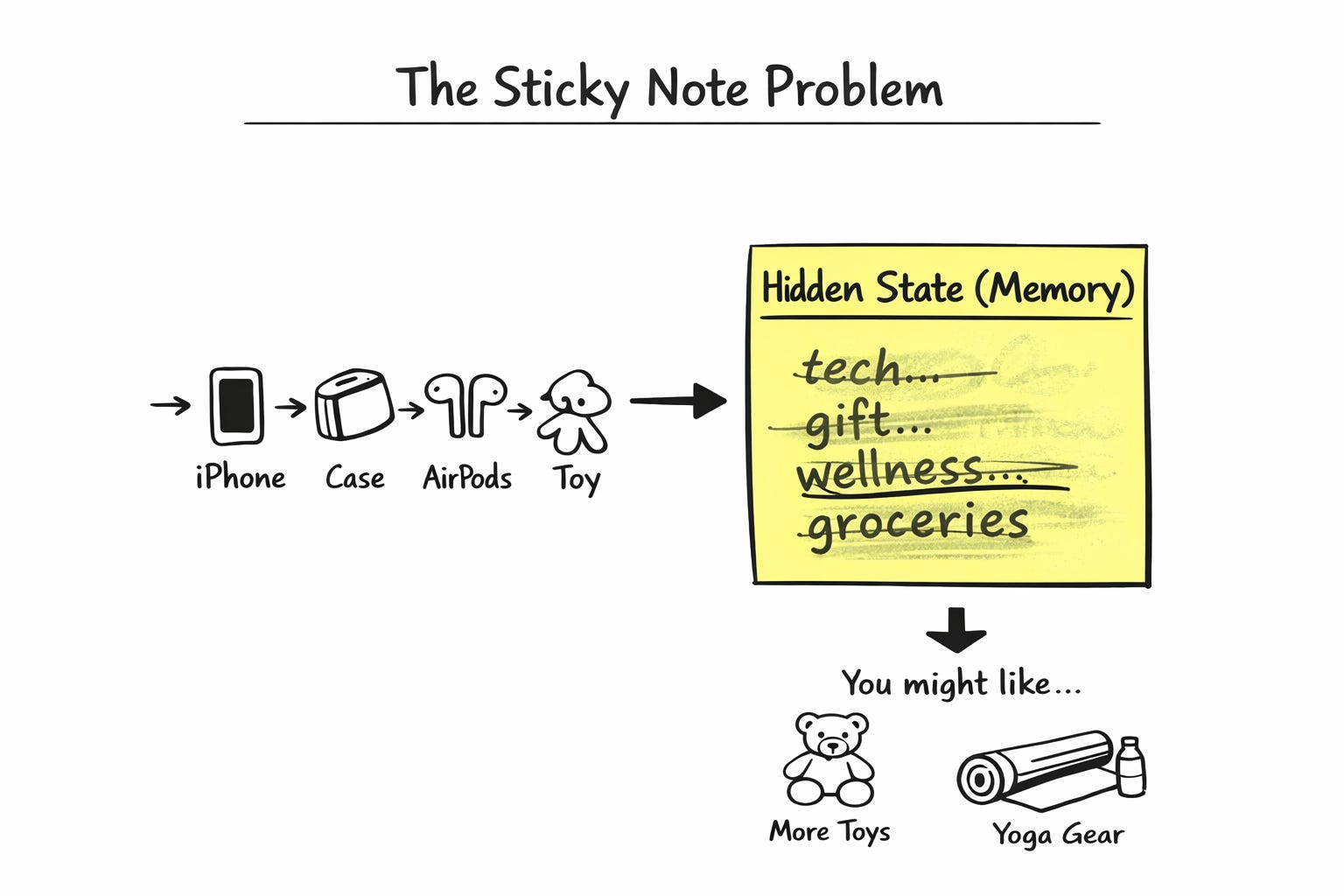
This is called Catastrophic Forgetting. And it is not a bug you can fix by tuning the model. It is a fundamental flaw in the architecture. The sticky note itself is too small to hold what it needs to hold.
Why This Breaks Product Experience
This has two costs that hit you directly as a PM.
The first cost is performance. Your model misses the highest-signal moments in a user’s journey because they get washed out by noise. A user who bought an iPhone three weeks ago is an obvious candidate for iPhone accessories. Your model does not see it. Your revenue per user suffers.
The second cost is explainability. You cannot tell a user why something was recommended. You cannot tell your leadership why the model did what it did. A single hidden vector is a black box even to the people who built it.
If you have ever been in a meeting where your head of product asks, “Why is the model recommending this?” and your ML lead says, “The embeddings suggest...”, you have lived this problem.
How Humans Actually Remember
Here is the interesting part. You do not have this problem.
If someone asks you what to get for a new baby, you do not scan every memory from your entire life. You pull up the specific episode of buying baby stuff for your niece last year. You focus on that. Everything else stays quiet in the background.
You have episodic memory. You can pull up specific moments on demand.
Your recommender does not have this. It only has the sticky note.
What if we gave the recommender episodic memory?
The Fix: A Memory Box, Not a Sticky Note
Instead of the single hidden vector, can we give every user a small memory box?
Think of the box as a row of 20 labelled drawers. Each drawer holds one past purchase. When you buy something new, it goes into a fresh drawer. The oldest drawer gets emptied to make space.
At any moment, your box has your last 20 purchases, sitting side by side.
The iPhone is in drawer 17.
The case in drawer 16.
The AirPods in drawer 15.
The toy in drawer 14.
The book in drawer 13.
And so on.
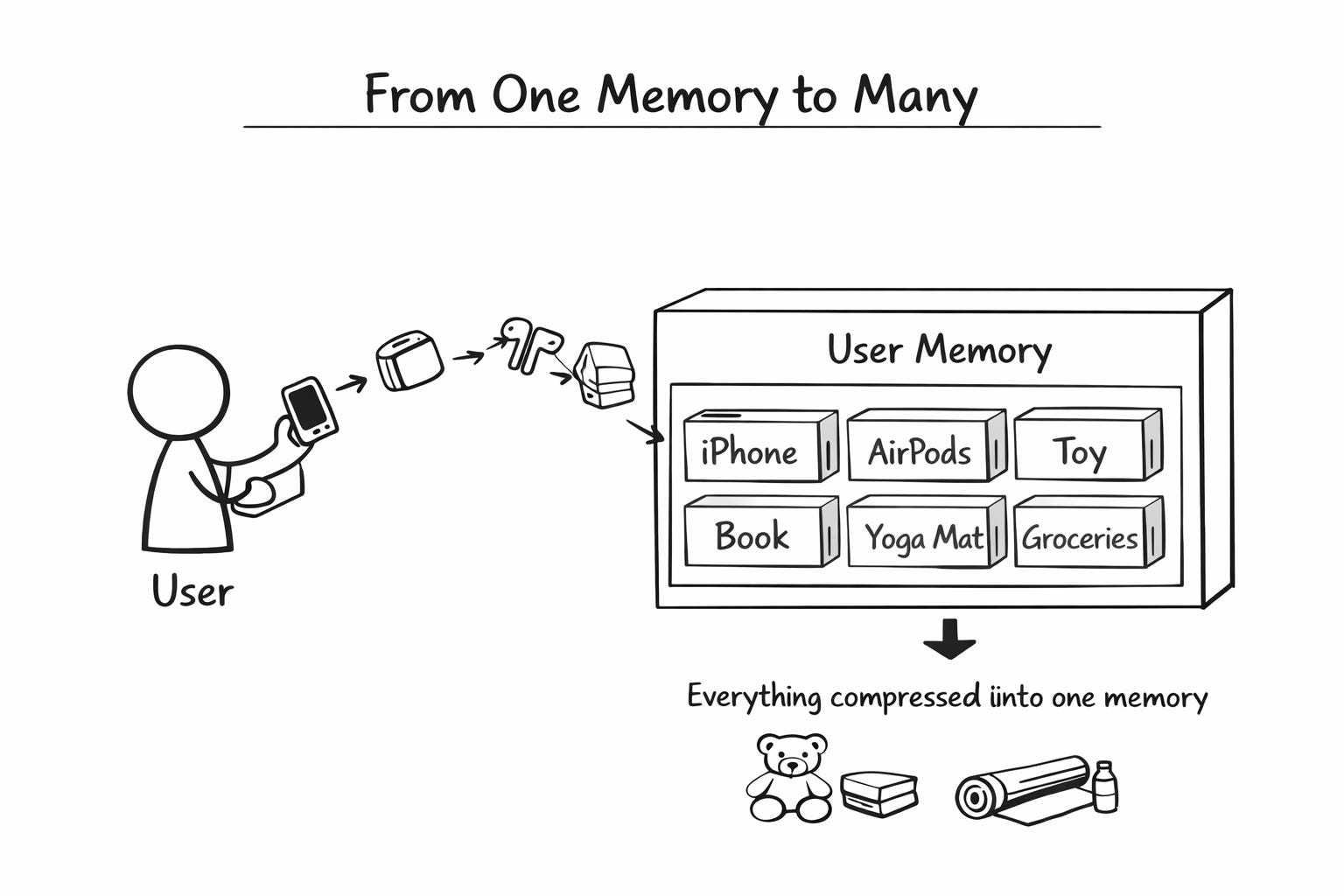
Nothing is smudged. Nothing is averaged. Each purchase sits cleanly in its own drawer.
Now, when you come back looking for a screen protector, the model does something clever. It does not read all 20 drawers equally. It asks a question.
“Which of these past purchases is most relevant to a screen protector?”
It scans each drawer, scores the similarity, and pays attention to the ones that match. The iPhone drawer lights up. The toy drawer stays dim. The book drawer stays dim.
The model pulls out the iPhone signal cleanly and recommends the perfect screen protector.
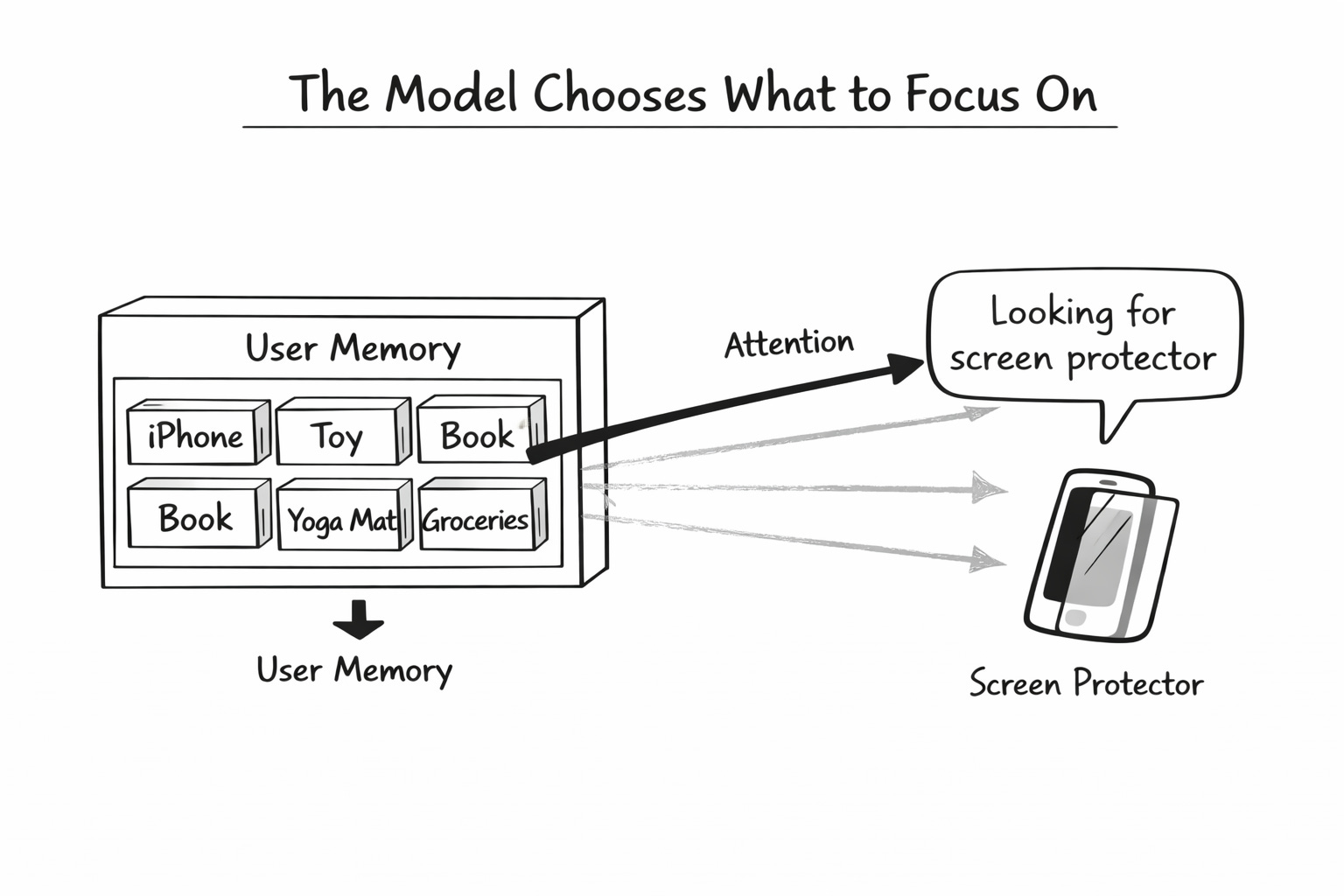
This is exactly how attention works in modern AI. The model decides what to focus on based on what it is trying to do right now.
Two Versions of the Same Idea
Here this we can do in two ways, both use the same core idea. They differ in what they store.
The first version is called item-level RUM.
Each drawer in the box holds an actual past purchase. iPhone in one drawer. AirPods in another. This is simple. It is also explainable. You can literally tell the user that we showed you this because of that iPhone you bought three weeks ago.The second version is called feature-level RUM.
Each drawer does not hold a purchase. It holds a preference. One drawer tracks your brand preference. Another tracks your price sensitivity. Another tracks your style preference. Every time you buy something, the drawers get gently updated. Buy an Apple product, and the brand drawer leans more towards Apple. Buy something cheap; the price is more budget-friendly.
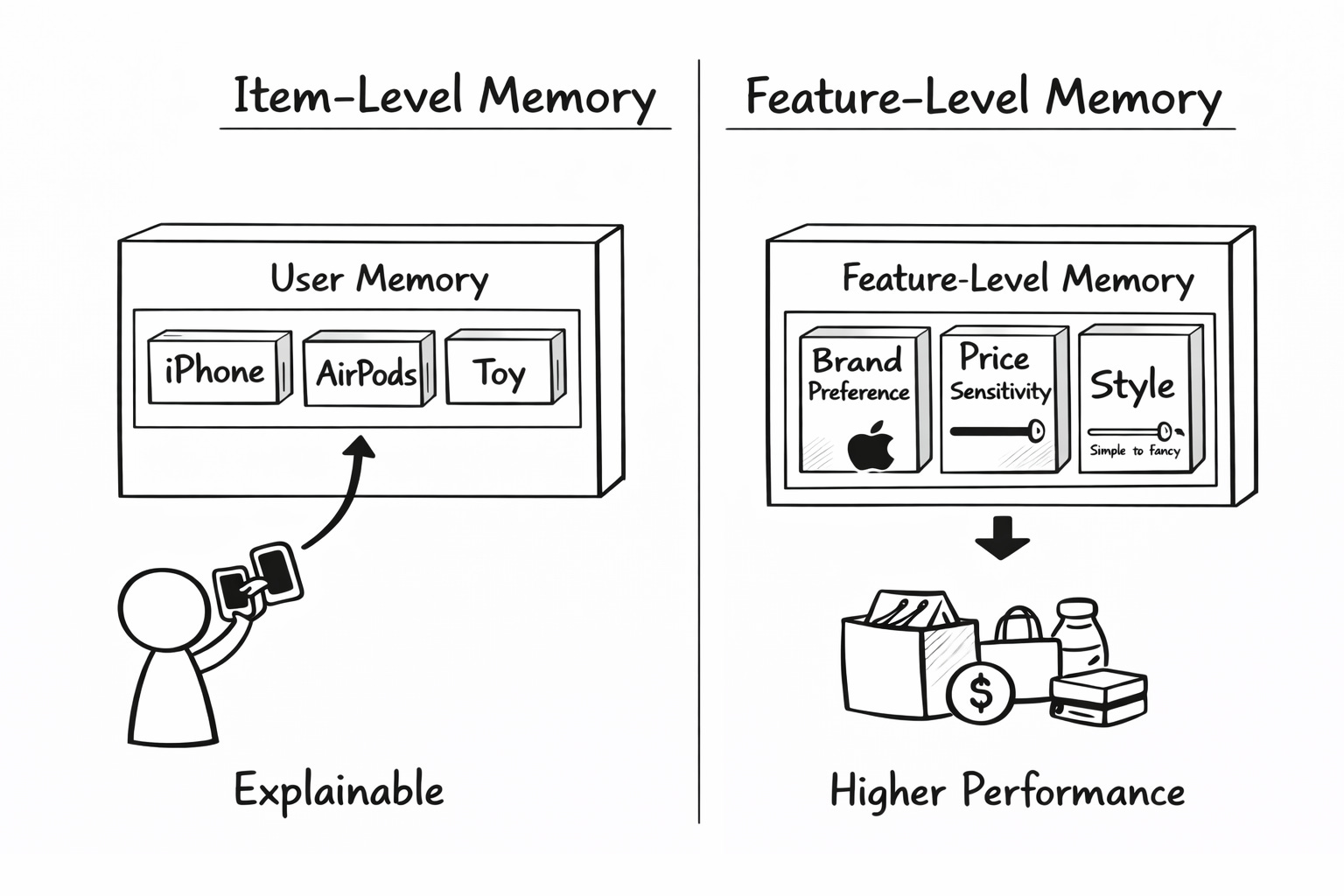
The second version tends to perform better. The first is easier to explain.
If you work in a domain that demands explainability, such as finance or healthcare, go item-level.
If you are running a pure engagement product where performance is everything, go feature-level.
How The Memory Updates
The item version is simple. New purchase comes in, oldest one gets kicked out. First in, first out. A 20-slot box always holds the last 20 purchases.
The feature version is more interesting.
When you buy something new, the model does two things.
First, it decides what to forget. If you just bought an Android phone, your brand preference for Apple should fade. The model computes a forget signal and uses it to gently erase the old preference.
Then it decides what to reinforce. Your brand preference for Android should go up. The model computes an add signal and writes it to the drawer.
The mental model is simple. Every time you buy something, the relevant drawers in your memory box get a small dusting-off followed by a small update.
The beautiful thing is that the model learns what to forget and what to reinforce on its own. You do not write rules. You show it millions of user sequences, and it figures out the pattern.
Thing which Product Manager needs to decide
Memory size
How many drawers per user? More drawers mean richer history, but more computing. 20 might work for e-commerce. For a content platform like TikTok, where users burn through items in seconds, you might want 50 or 100.
Item level or feature level
Explainability or performance. Pick one. You cannot have both.
Memory weighting
optimal weight for recent behaviour. Start there. Then an A/B test. Stable domains like books or music can push intrinsic weight higher. Volatile domains like news or short-form video need more memory weight.
Write strategy
For item level, first-in-first-out is fine. For the feature level, you need the forget-and-reinforce approach. It is more powerful. It is also harder to debug.
If this article changed how you think about memory, recommendation architectures, and AI system design, you will find much more depth in our AI PM course.
We cover these in 40+ Videos and 25+ Case Studies, along with AI PM interview questions from top AI companies.
About Author
Shailesh Sharma! I help PMs and business leaders excel in Product, Strategy, and AI using First Principles Thinking. Weekly Live Webinars/MasterClass ( Here )
 | A guest post by
|