
Two Versions of Every Click
Why Your Model and Your User Disagree on What Just Happened

Every click in your training data tells two stories.
Your model hears one. The user lived the other.
They are not the same story. And the gap between them is destroying your feed.
We are going to show you both versions, side by side, for every stage of the recommendation pipeline. By the time the two stories merge, you will understand position bias deeper than any offline metric can show you.
In our previous pieces, we covered how TikTok uses session-based RNNs and why recommenders suffer from catastrophic forgetting. This one is about a different failure. Your model remembers clicks. But it misremembers why they happened.
If you are preparing for AI PM interviews, position bias comes up constantly in recommendation system design rounds. We cover this and more in our course.
The Click
What your model recorded
User opened the app store. Saw App X at position 1. Clicked. Label = 1. App X is relevant.
What actually happened
User opened the app on the metro. Had 40 seconds before their stop. App X was the first thing on screen. They did not scroll. Did not compare. Saw one thing. Tapped it.
If App Y had been at position 1, they would have tapped App Y.
The click had nothing to do with App X. It had everything to do with position 1.
The Data
What your model sees:
Position 1 CTR is 0.25. Position 5 is 0.10. Position 15 is 0.03. Items at position 1 are 8x better than items at position 15.
What is actually true
95% of users see position 1. Maybe 60% reach position 5. Fewer than 20% get to position 15.
A great app at position 15 gets 0.03 CTR because nobody saw it. A mediocre app at position 1 gets 0.25 because everyone saw it.
The model has no way to tell these apart. It calls both numbers a preference.
The Loop
What your model believes
It trains weekly. Every cycle, the data confirms that items at the top are the best items. Their CTR is highest. Their scores go up. They stay at the top. The system is stable. The system is working.
What is actually happening?
Top items get more clicks because they are at the top. Those clicks inflate their CTR. Inflated CTR keeps them at the top. Next week, same thing.
A genuinely excellent app debuted at position 12 three weeks ago. CTR of 0.04. Not because users disliked it. Because most users never scrolled that far. The model scored it low. It dropped to 16. Then it disappeared.
Your feed is not ranking by quality. It is ranked by inertia.
This has two costs.
First, diversity dies. The same items win every cycle. New items cannot break through. Your feed feels stale. Engagement decays.
Second, revenue leaks. Your ranking function is f(CTR, bid). If CTR is inflated by position, you are overvaluing items that sit high and undervaluing items that bid high. That is money lost daily.
The Usual Fix (And Why It Fails)
Every team eventually notices something is off. The standard fix is simple. Add position as a feature.
The model sees [user features, item features, context, position]. It learns that clicks at position 1 should be discounted. Sounds reasonable.
What the team believes this achieves
The model now accounts for position. Bias is handled.
What actually happens at inference time?
The model needs a position value to produce a score. But the position has not been decided yet. That is what the ranking is supposed to determine.
You cannot feed a position as input when the position is the output.
So the team picks a default. Position 1 for all items. Or position 5. Or position 9.
They try position 1. They get Ranking A. They try position 5. They get Ranking B. Completely different. Different items in the top 5. Different user experience.
The ranking depends entirely on a number someone picked arbitrarily.
You are now running AB tests to find the best magic number. And the best number for one scenario does not transfer to another. The approach is a dead end.
The Question That Closes the Gap
Here is the question that resolves the two stories into one.
When a user clicks, what are they actually telling you?
Two things. Fused into a single signal.
First: I saw this item. This depends on the position. Position 1 is almost always seen. Position 20 has maybe a 10 per cent chance. This has nothing to do with the item.
Second: I wanted this item. This depends on the user, the item, and the context. This has nothing to do with position.
Every click is the product of these two.
P(click) = P(saw it) x P(wanted it, given I saw it)
Your model treats this product as one number. That is the entire problem. The fix is to split it.
How to solve this?
We can build two modules. Trains them together. Deploys them apart.
Module 1 is ProbSeen.
One input: position.
One output: the probability the user saw the item at that position. Think of it as a small curve. Position 1 outputs 0.95. Position 20 outputs 0.12.
Module 2 is pCTR.
Inputs: user profile, item features, context.
Output: the probability the user would click if they had seen it.
Position never enters pCTR.
During training, predicted click = ProbSeen x pCTR. This is compared against the actual click label. Standard cross-entropy loss.
Here is what makes it work. Both modules share the same loss. They train jointly. Gradients flow through both.
When the model sees that position 1 items get clicked more, the shared gradient forces a split. How much of that signal is visibility? ProbSeen takes it. How much is genuine preference? pCTR takes it.
Neither module can steal the other’s signal. Both are accountable for the same loss. The separation is automatic.
Why not train them separately? Because separate losses mean separate objectives. ProbSeen might absorb preference. pCTR might absorb position. The boundaries blur. Joint training forces a clean separation through coupled gradients.
At inference time, you throw away ProbSeen. You deploy only pCTR.
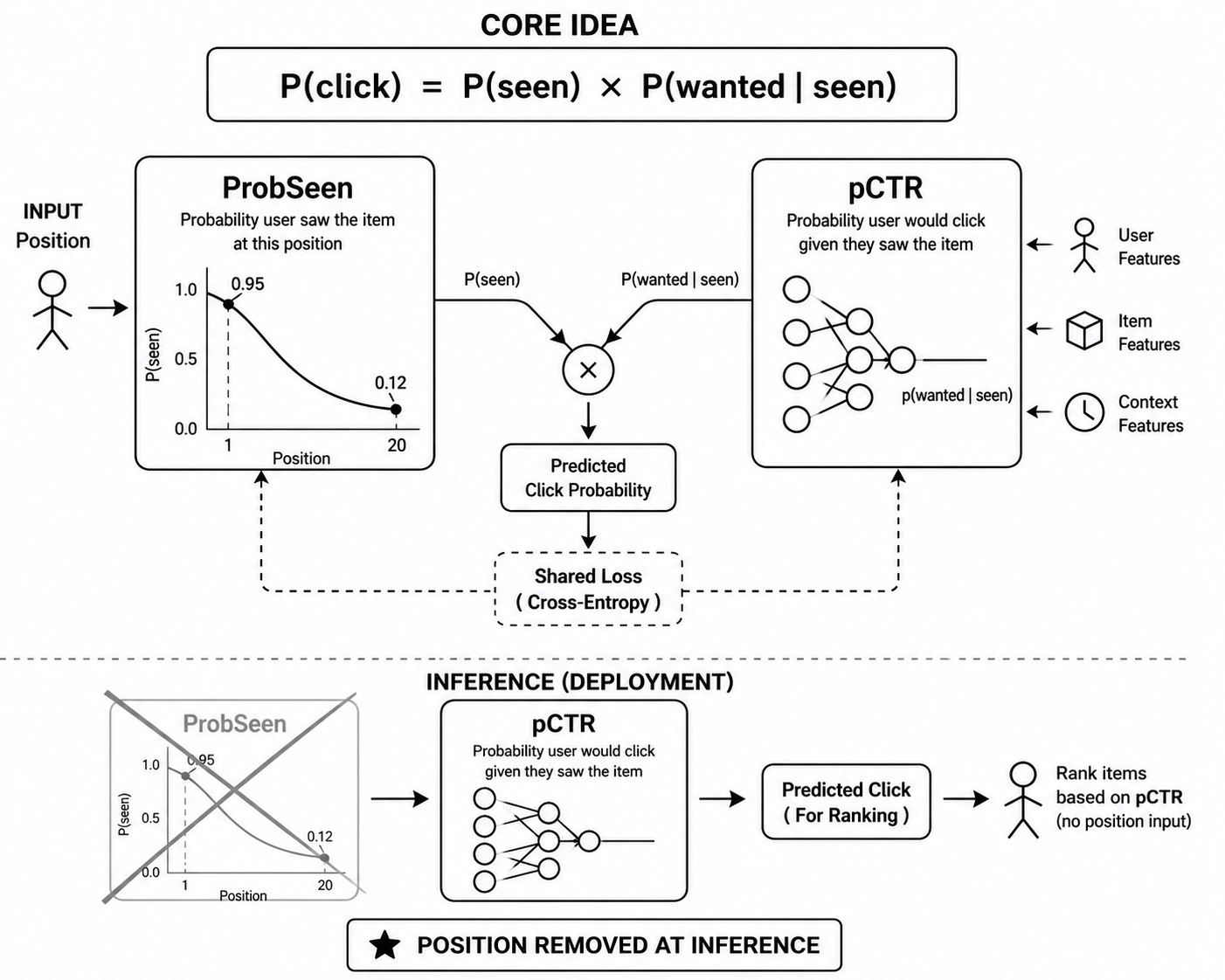
No position input needed. No default value. No magic number.
What your model now records: This user would click this item, regardless of where it is shown.
What actually happened: Same thing.
The two stories are finally one.
If this article changed how you think about position bias, CTR modelling, and ranking quality, you will find much more depth in our AI PM course Case Studies. (42+ Videos & 25+ Case Studies)
Check our highest-rated AI PM course (Including AI PM Interview Preparation) · 4.9/5 · 600+ enrollments → See testimonials and course details
About Author
Shailesh Sharma - I help PMs and business leaders excel in Product, Strategy, and AI using First Principles Thinking. Weekly Live Webinars/MasterClass (Here)