
What's OpenRAG? Future of RAG
AI for Product Managers


Before we move on, read these important articles
AI Product Metrics ( AI PM Interview Question )
In our last article, we discussed the massive Context Windows of modern LLMs; it’s time to upgrade ourselves.
Imagine you are a Senior Product Manager at YouTube.
You are in charge of building a new “Ask this Video” Generative AI feature.
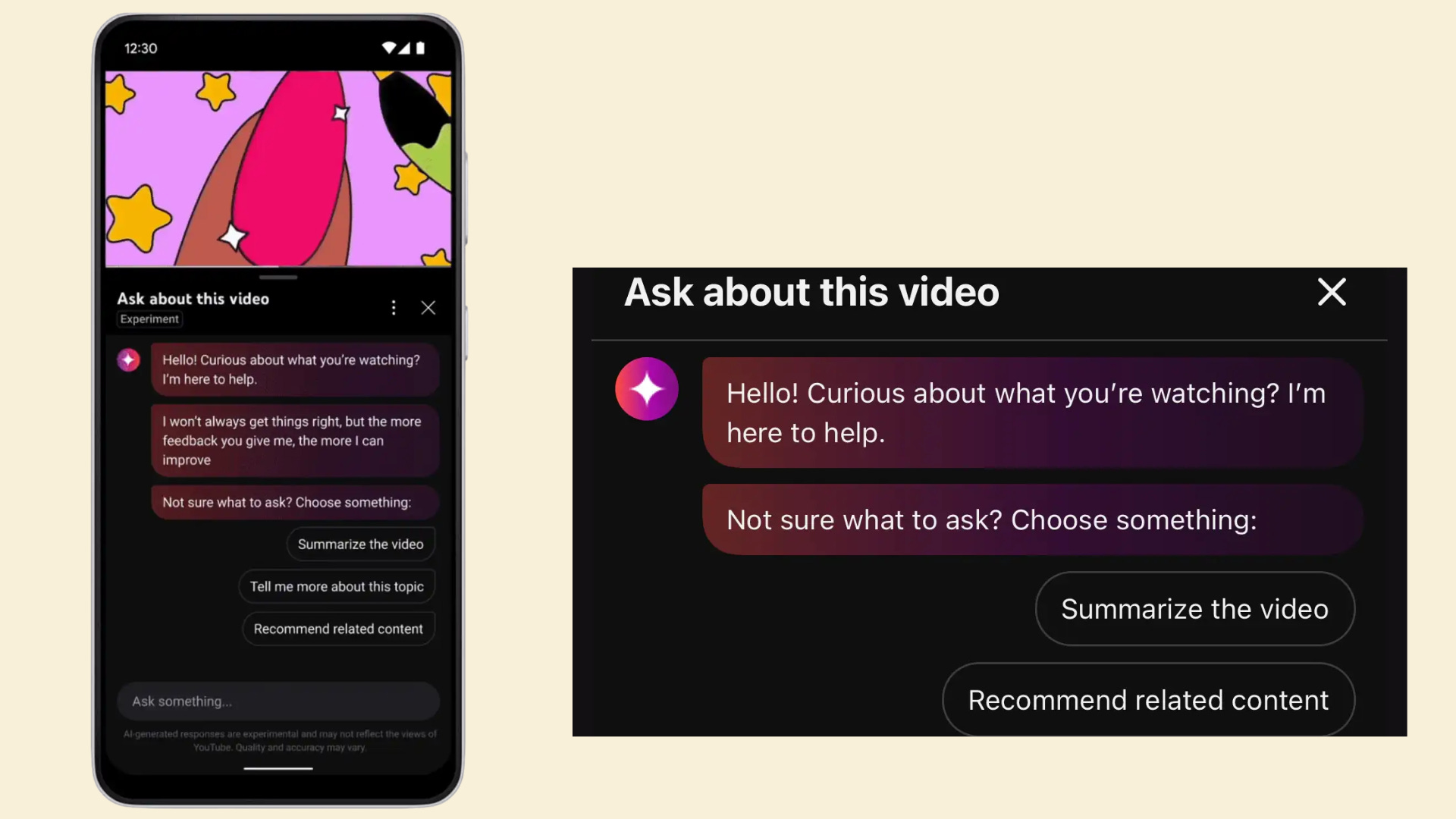
Ask this Video - feature is an AI-powered conversational tool on YouTube that allows viewers to interact directly with the content they are currently watching.
By analysing the video's transcript in real-time, it enables users to request summaries, extract specific facts, or clarify concepts without interrupting playback.
You have a massive problem: AI models are incredibly smart, but they know absolutely nothing about the 3-hour podcast a creator uploaded five minutes ago.
When a viewer clicks the “Ask” button and types, “Summarise the part where they discuss the new camera features and skip the sponsor read,” the AI cannot just guess the answer.
It needs the exact, up-to-the-minute context of that specific video.
How do you build a system that accurately leverages millions of hours of dynamic, unstructured video data without breaking the bank?
Option 1: Prompt Stuffing (The Context Window)
With new models boasting massive context windows, you could try to inject the entire 3-hour transcript, the uploader’s channel history, and the top 1,000 comments into the prompt every time a viewer asks a question.
But this has terrible Unit Economics. You pay per token. Stuffing a massive transcript into every single query will charge you a fortune, and it takes the model excessive time to process.
Plus, the model might get lost in the middle, confusing something said in minute 10 with something said in minute 150.
Option 2: Fine-Tuning the Model
You could retrain the underlying weights of the LLM on your massive database of YouTube transcripts.
But it misses Dynamic Context. Over 500 hours of video are uploaded to YouTube every single minute.
Fine-tuning is expensive, slow, and static. If a creator uploads a breaking news video at 2:00 PM, your fine-tuned model won’t know about it until the next massive training run.
Now, let’s see how RAG (Retrieval-Augmented Generation) solves the Problem.
But before that, let’s understand: What is OpenRAG?
OpenRAG is an open-source platform where all the necessary tools are tightly integrated, making it super easy to set up an effective agentic RAG system in just a few minutes.
Instead of spending months building a custom data pipeline to connect your AI to your video servers, OpenRAG gives you a pre-configured architecture out of the box.
Why do we need OpenRAG?
We need it because blindly feeding data to AI is inefficient and inaccurate.
Instead of reading the whole 3-hour transcript, RAG searches the database, finds the exact two paragraphs from minute 45 where the camera is discussed, and feeds only those specific details to the AI. This keeps token costs incredibly low and responses lightning-fast.
You need a system that gives you complete freedom to swap out underlying AI models or connect totally new external databases (like a database for YouTube Shorts) without writing complex backend code.
How OpenRAG Works
For a complete and proper RAG system to work, it requires three main components. OpenRAG achieves this with three powerful tools:
1. Docling (Intelligent Data Entry)
Suppose you are processing a highly technical tutorial video.
The data isn’t just spoken words; it’s a mix of auto-generated transcripts, on-screen text (OCR), and chapter metadata. Traditional parsers dump all this raw text into a file, destroying the timeline structure.
Docling is the smart parser. It identifies these different components and extracts them properly, keeping timestamps aligned with the text. If this isn’t done right, your system fills with junk data, and the AI quotes a timestamp that points to the wrong part of the video.
2. OpenSearch (Fast Searching)
Once Docling processes the video transcripts and metadata, the data goes directly to OpenSearch.
This is your memory bank. It stores video data chunks as vector representations (mathematical embeddings of text).
When a viewer asks, “When do they talk about the battery life?”, OpenSearch performs similarity searches to retrieve the exact transcript chunks that mathematically match that concept, even if the speaker said power efficiency instead of battery life.
3. Langflow (The Main Wiring)
Think of Langflow as the execution engine.
It connects your AI models, your OpenSearch database, and the YouTube app interface together.
It provides a Visual Studio UI where you can make custom changes directly in the workflow. When you add your transcript database here, you give it a unique, descriptive name.
This is crucial so the AI agent knows to pull from the video content.
Challenges with OpenRAG Systems
If Docling fails to parse a poorly auto-captioned video (where words are mumbled or overlapping), OpenSearch retrieves garbage text, and the LLM confidently hallucinates an incorrect answer.
Vector databases can be computationally heavy. Efficient indexing is required so viewers aren’t left staring at a loading spinner.
Adding an orchestration layer (Langflow) and a retrieval step adds latency before the LLM even begins generating the first word of the response.
If you are managing an OpenRAG-based YouTube AI companion, track these:
Retrieval Latency: How many milliseconds does it take for OpenSearch to find the relevant 30-second chunk of the transcript?
Time to First Token (TTFT): How long does the user wait from clicking “Ask” to seeing the very first word generated by the AI?
Timestamp Accuracy: Did the retrieval engine actually fetch the correct segment? If the AI provides a “Jump to 12:04” link, users will instantly downvote the answer if the timestamp is wrong.
Token Efficiency: How many tokens are you sending in the augmented prompt vs. how many were necessary? This directly impacts the feature’s computing cost at YouTube scale.

For New Year, we are giving EXTRA 60% OFF on our AI PM Flagship Course for very limited Time | ( 35+ Videos ) & ( Extra 25+ Real Case studies as well )
Coupon Code — NYE26 , Course Link — Click Here
About Author
Shailesh Sharma! I help PMs and business leaders excel in Product, Strategy, and AI using First Principles Thinking. For more, check out my AI Product Management Course, PM Interview Mastery Course, Cracking Strategy, and other Resources
 | A guest post by
|